1.Abstract
本文提出了一种新的方法,用于长时间未修剪视频序列中人体动作的时间检测。我们引入单流时序动作提案( SST ),这是一种新的有效且高效的生成时序动作提案的深度架构。我们的网络可以在很长的输入视频序列上以单个流连续运行,而不需要将输入分割成短的重叠片段或时间窗口进行批处理。我们在实验中证明了我们的模型在时间动作提议生成任务上的表现优于当前最先进的模型,同时达到了一些文献中最快的处理速度。最后,我们证明了将SST建议与现有的动作分类器结合使用,可以提高最先进的速度。
本论文主要提出了一个新进的Proposals方法,用于目标检测和动作识别。
2.Introduction
视频中记录了大量关于人类行为动作的信息,要想处理这些数据,计算机视觉算法需要能够进行人类动作识别和检测的能力。
先前的方法:
- 一开始动作识别被简单的看作是视频分割,也就是把原本的长视频分割成包含单个动作的小片段,但是由于相机记录人类动作是持续不断进行的,所以如果要实现这种想法,算法必须在识别发生动作的起止时间的同时识别动作的种类。但是动作的数量和持续时间可能会有很大的变化,与视频长度相比,动作间隔可以很短。
- 利用滑动的时间窗口在多个时间尺度上把视频分割成大量重叠内容包含动作的Proposal(提案)的片段,然后再用分类器进行分类。该方法计算量大,需要重复多次处理重叠窗口。
本文的方法:
- 提出了长视频序列中进行时序动作建议的框架,该框架只需要在单个通道中处理整个视频。这代表着这个框架可以分析任意长度的视频,不需要单独处理重叠的时间窗口。
主要贡献:
- 引入一个新的架构(SST)用于时序动作提案的生成,该架构可以在单遍视频中运行。可以一次性处理长视频序列,只向前传播一次就能处理完整个video,而不需要使用重叠的时序滑动窗口。框架是基于RNN构建的网络。
- 可以处理long video sequence,只需要向前传播一次就能处理完整个video,可以处理任意长度的video,不需要处理重叠的时间窗口。
- 在proposal generation task上取得了顶尖成果。
3.Related Work
回顾了与视频动作分类、时空动作检测以及循环网络在序列建模中的应用相关的研究。在动作分类方面,大量研究关注于从短视频片段中分类动作。然而,这些方法通常无法很好地处理长视频序列,其中动作的时间跨度相对较小,大部分视觉输入被视为背景。
在时空动作检测方面,已有的方法主要通过滑动窗口的方式密集地应用动作分类器。最近,时空动作提议(Temporal Action Proposals)被引入,以更有效地对少量的时间窗口应用动作分类器。这些提议通常是通过学习方法生成的,例如使用字典学习或循环神经网络架构。
此外,论文还讨论了物体检测领域的相关工作,特别是如何通过深度网络架构直接输出提议,而不是通过多次传递来实现。最后,文章探讨了循环神经网络(RNN)在长序列处理方面的应用和性能,这对于视频分析尤为重要。
关键:序列化、连续化,判断动作不止要看动作本身还要看前后相关的帧。
4.Model
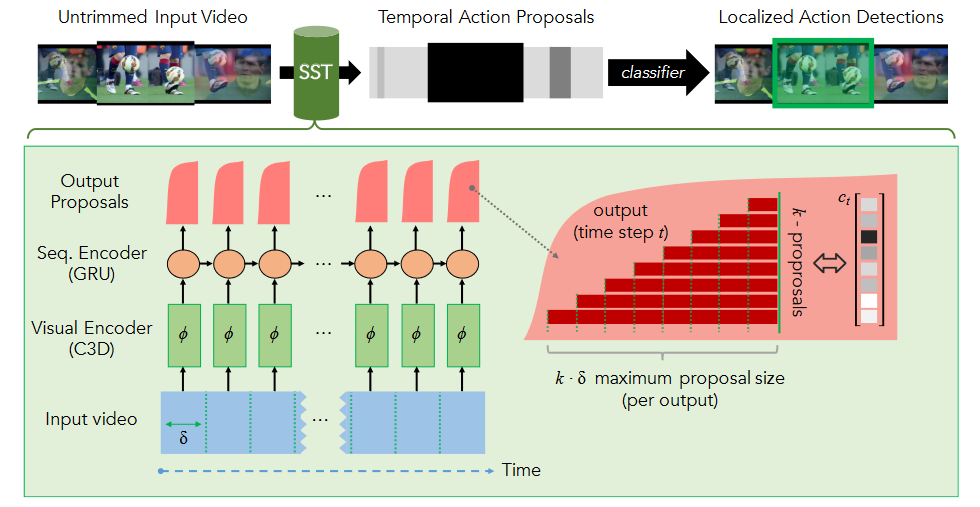
SST模型(Single-Stream Temporal Action Proposals)运作具体细节:
输入:
- 输入:长未剪辑视频序列 $X = {x_l}^L_{l=1}$,L代表帧数。
- 视觉编码:通过3D-卷积(C3D:能在小的时间分辨率δ内有效地捕捉视觉和运动信息)网络处理视频输入,获取每个时间步的C3D特征向量 $v_t$。
序列编码:
- 使用门控循环单元(GRU)架构,比传统LSTM单元更高效。
- 每个时间步 $t$,序列编码器接收对应的编码C3D特征向量 $v_t$ 作为输入。
- GRU更新规则:
- 重置门 $r_t = \sigma_r(W_r v_t + U_r h_{t-1} + b_r)$
- 更新门 $z_t = \sigma_z(W_z v_t + U_z h_{t-1} + b_z)$
- 新状态 $\tilde{h_t} = \tanh(Wv_t + r_t \odot (U h_{t-1}) + b)$
- 最终状态 $h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t$
随着视频序列编码的进行逐步确定视频到底做了什么动作,这里接受的是降维后的C3D特征信息,到这一步,收集信息直到确定某个动作已经发生了,与此同时,扔掉不相关的背景信息。从流程上可以看出每一个time step所接收的信息包括两部分,一部分是来自visual encoding的经过降维的C3D特征,一部分是上一步的time step,输出也是两部分,proposal和下一个time step,这里使用的是GRU进行处理
输出:
- 目标:每个时间步 $t$ 生成多个提议的置信度分数。
- 输出层设计:在每个时间步考虑多种时间尺度的提议,这些提议都以时间 $t$ 结束。
- 提议置信度得分:$c_{jt} = \sigma_o(W_{oj} \cdot h_t)$。
- 所有考虑的提议在时间 $t$ 有固定的结束边界,模型考虑时间步长为 $1, 2, \ldots, k$ 的提议,对应 $\delta, 2\delta, \ldots, k\delta$ 帧。
每一个time step都会输出一个confidence score 这些score对应着k组从$b_t-1$到$bt$的proposal,每次output最大值就是k$\delta$frame的proposal。需要注意的是这里他用了一个single forward pass at each time step ,也就是说他每次找proposal都只需要一次前向传播就能处理完整个视频序列
但是这里其实相当于输出了一系列的概率值,并没有确定哪一个是真正的proposal,所以还需要一个groudtruth来评定哪一个是最好的。
训练:
- 使用加权二值交叉熵目标进行训练。
- 训练目标:$L(c, X, y) = - \sum_{j=1}^k [w_{0j} y_{tj} \log c_{jt} + w_{1j} (1 - y_{tj}) \log(1 - c_{jt})]$
- 通过密集抽样重叠训练视频段来模拟测试操作条件,提高模型的鲁棒性。
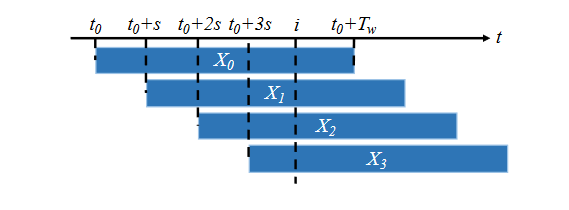
训练数据的生成:
- 对于每个训练视频,通过以长度为 $(T_w)$ 的滑动窗口方式提取片段,其中$ (T_w = L_w / \delta)$,步长为 。$s$
- 设置 $(L_w \gg k\delta)$,以模拟长序列的操作,避免隐藏状态饱和。
训练过程:
- 训练实例与视频中的时间间隔对应的真值标签相关联,网络将每个时间间隔分类为正面或负面的动作提议。
- 使用加权二值交叉熵目标进行训练,对于训练视频 $X$,在时间$t$的损失由下式给出: \(L(c, t, X, y) = -\sum_{j=1}^k \left[w_{0j} y_{tj} \log c_{jt} + w_{1j} (1 - y_{tj}) \log(1 - c_{jt})\right]\) 其中,$(w_{0j})$ 和 $(w_{1j})$是根据训练集中每个尺度$j$的正负提议的频率计算出来的权重,$c$是网络的输出。
- 在所有训练实例$X$上的总损失为: \(L_{\text{train}} = \sum_{(X, y) \in X} \sum_{t=1}^{T_w} L(c, t, X, y)\)
关键点:
- 训练时,通过密集采样重叠的训练视频段来模拟测试操作条件,使网络对非修剪视频中的背景内容不敏感,同时保留相关上下文。
- 在每个时间步中,通过不同的上下文多次考虑原始视频序列的每个时间步,以增强预测和编码对隐藏状态初始值的鲁棒性。
- 每一次取样都使用label来进行标记,把这些已经选出来的$proposal$分为$positive$和$negative$,比如说在上图的$X_0$,此时此刻计算他的$IOU$值,如果超过0.5:label为1,低于0.5:label为0,做一个二分类。
上述所提到的训练过程是有监督学习
5.Experiment
接着把$SST$网络和$SCNN-prop$等相关方法在等量的proposal时候进行比较,在不同的tIOU范围内的召回率进行对比。很明显$SST$明显优于其他网络。
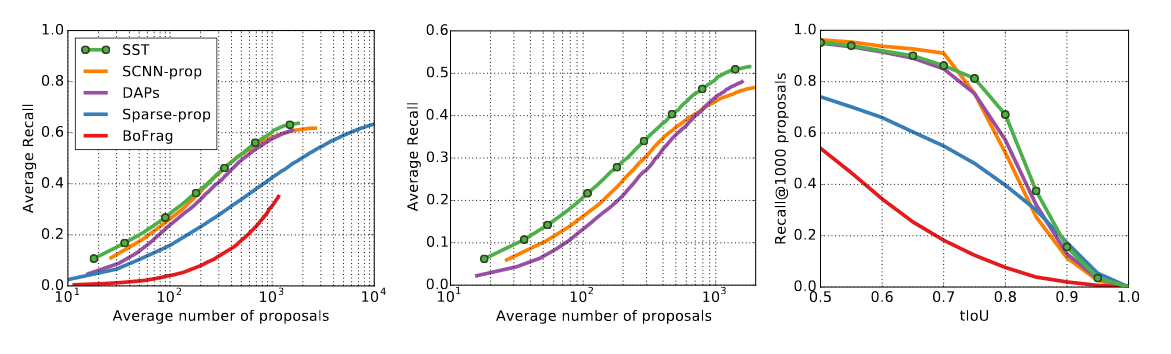
对比可以看出$SST$和其他方法相比,在$IOU$较高的状态下效率更高,也就是说我们可以进行密集取样捕获真实的动作片段以便分辨出视频动作。
$SST$对应的ground truth(有监督学习的训练集的分类准确性)优于先前提出的新进方法$DAPs$。
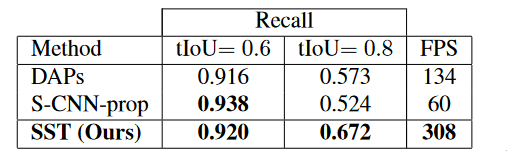
另外相比其他的方法来说,因为不需要重复添加大量的窗口,$SST$的运行速度更快。
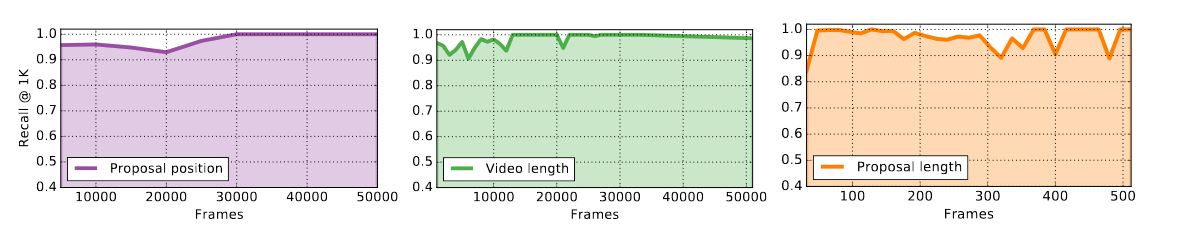
模型鲁棒性来讲,$SST$可以在长视频序列下很好的运作不会影响性能。

网络扩展性上,作者提出了可以和各种分类器配合一起使用,表现的也比较好。

6.Conclusion
作者提出了一种新的架构:$SST$,用于时序动作提案,可以在长视频序列上以高处理速度运行。同时作者也利用该方法将输入的视频数据作为单流进行处理,并且在评估时构建没有重叠的滑动窗口,提高了运行速度。
模型在动作提议(Proposals)任务上达到了最先进的性能,并且当作为一个完整的检测架构的一部分时,以更少的提议提供了有效的动作定位性能。
7.相关链接
论文地址
作者源码地址
Pytorch版