1.任务
先一个个实现ResNets的网络模块,然后将这些模块拼到一起构建ResNets来实现图像分类 。
2.导入依赖包
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshow
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
3.背景介绍
上篇文章建立第一个卷积神经网络。近年来,神经网络变得越来越深,最先进的网络从只有几层(例如,AlexNet)发展到超过一百层。
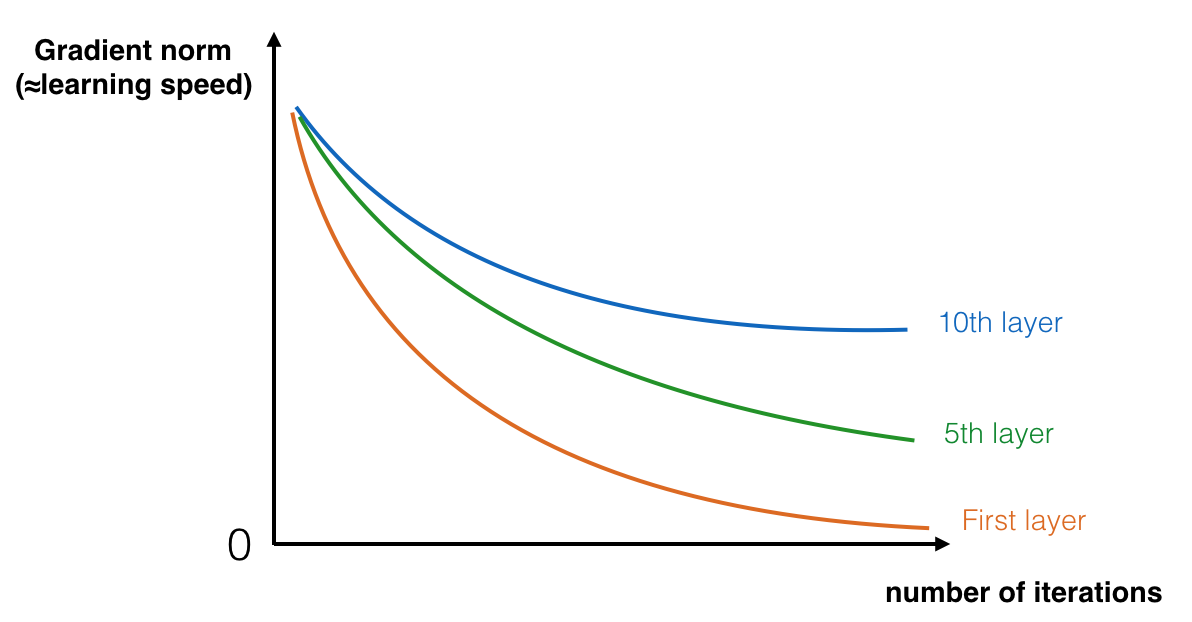
非常深网络的主要优点是它可以表示非常复杂的函数。它还可以在许多不同的抽象层次上学习特征,从较低层的边缘到较深层的非常复杂特征。然而,使用更深的网络并不总是有帮助。训练它们的一个巨大障碍是梯度消失:非常深的网络通常具有迅速趋近于零的梯度信号,从而使梯度下降变得非常缓慢。更具体地说,在梯度下降过程中,当你从最后一层反向传播回第一层时,你在每一步上都在乘以权重矩阵,因此梯度可以迅速指数级地减小到零(或者,在极少数情况下,指数级地增长并“爆炸”到非常大值)。
在训练过程中,你可能会看到随着训练的进行,较早层的梯度的大小(或范数)迅速减小到零:
4.创建一个ResNet(残差网络)

左侧的图像显示了网络的“主要路径”。右侧的图像在主要路径上添加了一个快捷方式。通过将这些ResNet块堆叠在一起,您可以形成一个非常深的网络。
我们还看到,具有快捷方式的ResNet块使得其中一个块学习恒等函数变得非常容易。这意味着您可以在几乎没有损害训练集性能的风险下堆叠额外的ResNet块。(还有一些证据表明,学习恒等函数的容易程度 - 甚至比跳过连接帮助解决梯度消失问题 - 解释了ResNet的卓越性能)
ResNet网络主要包含两个模块(The identity block、The convolutional block)
4.1The identity block
身份块是ResNet中使用的标准块,对应于输入激活(比如 $a^{[l]}$)与输出激活(比如 $a^{[l+2]}$)具有相同维度的情况。为了详细说明ResNet的身份块中发生的不同步骤,这里有一个替代图表展示了各个步骤:
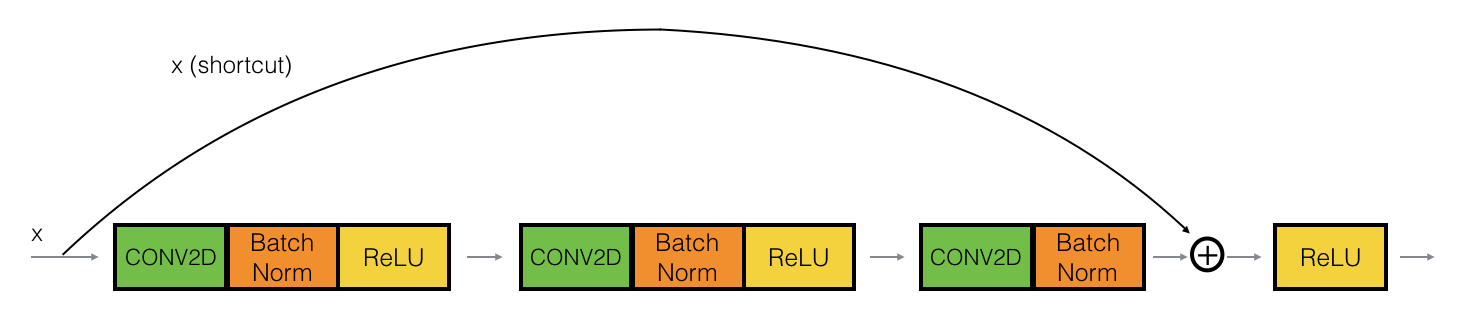
主路径的第一部分:
- 第一个CONV2D有
$F_1$个形状为 (1,1) 的滤波器,步长为 (1,1)。它的填充是“有效的”,其名称应该是conv_name_base + '2a'。使用0作为随机初始化的种子。 - 第一个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2a'。 - 然后应用ReLU激活函数。这没有名称和超参数。
主路径的第二部分:
- 第二个CONV2D有
$F_2$个形状为$(f,f)$的滤波器,步长为 (1,1)。它的填充是“相同的”,其名称应该是conv_name_base + '2b'。使用0作为随机初始化的种子。 - 第二个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2b'。 - 然后应用ReLU激活函数。这没有名称和超参数。
主路径的第三部分:
- 第三个CONV2D有
$F_3$个形状为 (1,1) 的滤波器,步长为 (1,1)。它的填充是“有效的”,其名称应该是conv_name_base + '2c'。使用0作为随机初始化的种子。 - 第三个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2c'。注意,在这个组件中没有ReLU激活函数。
最后一步:
- 快捷方式和输入一起相加。
- 然后应用ReLU激活函数。这没有名称和超参数。
代码:
# GRADED FUNCTION: identity_block
def identity_block(X, f, filters, stage, block):
"""
实现了图3中定义的身份块
参数:
X -- 输入张量,形状为 (m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径中间卷积层窗口的形状
filters -- Python整数列表,定义主路径中卷积层的滤波器数量
stage -- 整数,用于根据网络中的位置命名层
block -- 字符串/字符,用于根据网络中的位置命名层
返回:
X -- 身份块的输出,张量形状为 (n_H, n_W, n_C)
"""
# 定义命名基础
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 检索滤波器
F1, F2, F3 = filters
# 保存输入值。稍后需要将其加回主路径。
X_shortcut = X
# 主路径的第一部分
X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(1,1), padding='valid', name=conv_name_base + '2a', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)
X = Activation('relu')(X)
# 主路径的第二部分(约3行代码)
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding="same", name=conv_name_base + '2b', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
# 主路径的第三部分(约2行代码)
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding="valid", name=conv_name_base + '2c', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
# 最后一步:将快捷方式值添加到主路径,然后通过RELU激活函数(约2行代码)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return X
部署:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
输出:
out = [0.19716813 0. 1.3561227 2.1713073 0. 1.3324987 ]
4.2The convolutional block
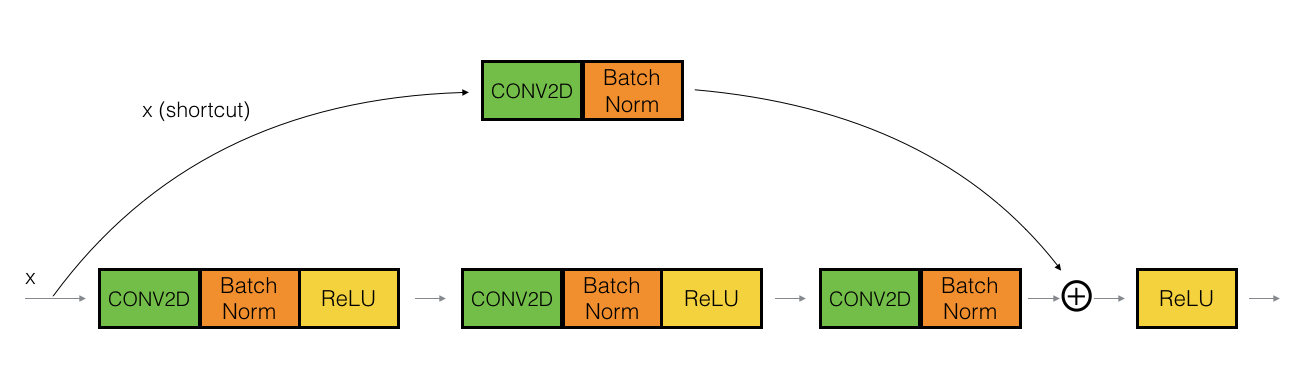
快捷路径上的CONV2D层用于将输入 $x$ 调整至不同的维度,以便在最终添加步骤中实现快捷路径值与主路径的维度匹配。(这与课堂上讨论的矩阵 $W_s$ 扮演相似的角色。)例如,要将激活维度的高度和宽度减少2倍,你可以使用步长为2的1x1卷积。快捷路径上的CONV2D层不使用任何非线性激活函数。其主要角色是仅应用(学习的)线性函数来降低输入的维度,以便后续添加步骤中的维度匹配。
卷积块的细节如下。
主路径的第一部分:
- 第一个CONV2D有 $F_1$ 个形状为 (1,1) 的滤波器,步长为 (s,s)。它的填充是“有效的”,其名称应该是
conv_name_base + '2a'。 - 第一个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2a'。 - 然后应用ReLU激活函数。这没有名称和超参数。
主路径的第二部分:
- 第二个CONV2D有 $F_2$ 个形状为 (f,f) 的滤波器,步长为 (1,1)。它的填充是“相同的”,其名称应该是
conv_name_base + '2b'。 - 第二个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2b'。 - 然后应用ReLU激活函数。这没有名称和超参数。
主路径的第三部分:
- 第三个CONV2D有 $F_3$ 个形状为 (1,1) 的滤波器,步长为 (1,1)。它的填充是“有效的”,其名称应该是
conv_name_base + '2c'。 - 第三个BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '2c'。注意,在这个组件中没有ReLU激活函数。
快捷路径:
- CONV2D有 $F_3$ 个形状为 (1,1) 的滤波器,步长为 (s,s)。它的填充是“有效的”,其名称应该是
conv_name_base + '1'。 - BatchNorm 正在规范化通道轴。它的名字应该是
bn_name_base + '1'。
最后一步:
- 将快捷路径和主路径的值相加。
- 然后应用ReLU激活函数。这没有名称和超参数。
代码:
# GRADED FUNCTION: convolutional_block
def convolutional_block(X, f, filters, stage, block, s=2):
"""
实现图4中定义的卷积块
参数:
X -- 输入张量,形状为 (m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径中间卷积层窗口的形状
filters -- Python整数列表,定义主路径中卷积层的滤波器数量
stage -- 整数,用于根据网络中的位置命名层
block -- 字符串/字符,用于根据网络中的位置命名层
s -- 整数,指定要使用的步幅
返回:
X -- 卷积块的输出,张量形状为 (n_H, n_W, n_C)
"""
# 定义命名基础
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 检索滤波器
F1, F2, F3 = filters
# 保存输入值
X_shortcut = X
##### 主路径 #####
# 主路径的第一部分
X = Conv2D(F1, (1, 1), strides=(s, s), name=conv_name_base + '2a', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)
X = Activation('relu')(X)
# 主路径的第二部分(约3行代码)
X = Conv2D(F2, (f, f), strides=(1, 1), padding="same", name=conv_name_base + '2b', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
# 主路径的第三部分(约2行代码)
X = Conv2D(F3, (1, 1), strides=(1, 1), name=conv_name_base + '2c', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
##### 快捷路径 #### (约2行代码)
X_shortcut = Conv2D(F3, (1, 1), strides=(s, s), name=conv_name_base + '1', kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3, name=bn_name_base + '1')(X_shortcut)
# 最后一步:将快捷路径的值加到主路径上,然后通过RELU激活函数(约2行代码)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return X
部署:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
输出:
out = [0.09018463 1.2348977 0.46822017 0.0367176 0. 0.65516603]
4.3创建ResNet
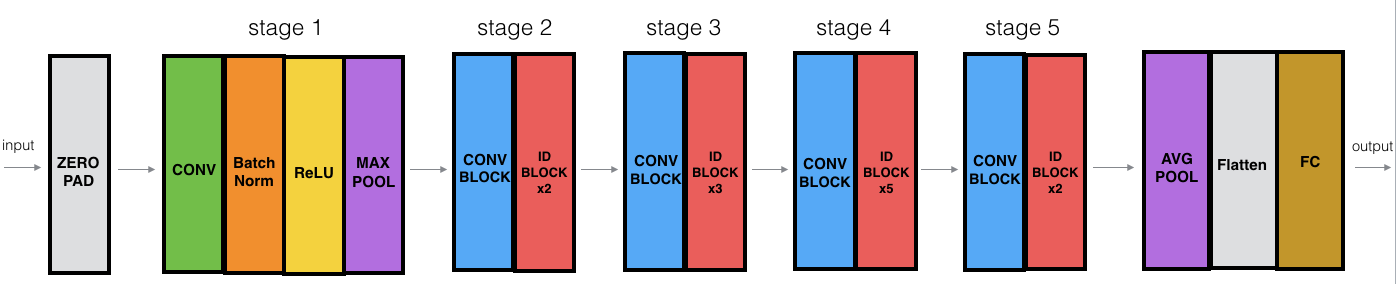
ResNet-50模型的具体细节如下:
- 零填充使用 (3,3) 的填充对输入进行填充
- 第1阶段:
- 2D卷积有64个形状为 (7,7) 的滤波器,使用 (2,2) 的步长。它的名称是“conv1”。
- BatchNorm 应用于输入的通道轴。
- MaxPooling 使用 (3,3) 的窗口和 (2,2) 的步长。
- 第2阶段:
- 卷积块使用三组大小为 [64,64,256] 的滤波器,“f”为3,“s”为1,块是“a”。
- 2个恒等块使用三组大小为 [64,64,256] 的滤波器,“f”为3,块是“b”和“c”。
- 第3阶段:
- 卷积块使用三组大小为 [128,128,512] 的滤波器,“f”为3,“s”为2,块是“a”。
- 3个恒等块使用三组大小为 [128,128,512] 的滤波器,“f”为3,块是“b”,“c”和“d”。
- 第4阶段:
- 卷积块使用三组大小为 [256, 256, 1024] 的滤波器,“f”为3,“s”为2,块是“a”。
- 5个恒等块使用三组大小为 [256, 256, 1024] 的滤波器,“f”为3,块是“b”,“c”,“d”,“e”和“f”。
- 第5阶段:
- 卷积块使用三组大小为 [512, 512, 2048] 的滤波器,“f”为3,“s”为2,块是“a”。
- 2个恒等块使用三组大小为 [512, 512, 2048] 的滤波器,“f”为3,块是“b”和“c”。
- 2D平均池化使用 (2,2) 形状的窗口,其名称是“avg_pool”。
- 扁平化没有任何超参数或名称。
- 全连接(密集)层使用softmax激活将其输入减少到类别数。它的名称应该是
'fc' + str(classes)。
代码:
# GRADED FUNCTION: ResNet50
def ResNet50(input_shape=(64, 64, 3), classes=6):
"""
实现流行的ResNet50网络,结构如下:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
参数:
input_shape -- 数据集图像的形状
classes -- 整数,类别数
返回:
model -- Keras中的Model()实例
"""
# 定义输入为具有input_shape形状的张量
X_input = Input(input_shape)
# 零填充
X = ZeroPadding2D((3, 3))(X_input)
# 第1阶段
X = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name='bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
# 第2阶段
X = convolutional_block(X, f=3, filters=[64, 64, 256], stage=2, block='a', s=1)
X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')
X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')
# 第3阶段(约4行代码)
X = convolutional_block(X, f=3, filters=[128, 128, 512], stage=3, block='a', s=2)
X = identity_block(X, 3, [128, 128, 512], stage=3, block='b')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='c')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='d')
# 第4阶段(约6行代码)
X = convolutional_block(X, f=3, filters=[256, 256, 1024], stage=4, block='a', s=2)
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='b')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='c')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='d')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='e')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='f')
# 第5阶段(约3行代码)
X = convolutional_block(X, 3, [512, 512, 2048], stage=5, block='a', s=2)
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='b')
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='c')
# AVGPOOL(约1行代码)。使用 "X = AveragePooling2D(...)(X)"
X = AveragePooling2D((2, 2), name="avg_pool")(X)
# 输出层
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer=glorot_uniform(seed=0))(X)
# 创建模型
model = Model(inputs=X_input, outputs=X, name='ResNet50')
return model
部署:
model = ResNet50(input_shape = (64,64,3),classes = 6)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
测试输出:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
训练:
model.fit(X_train, Y_train, epochs = 2, batch_size = 32)
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
训练输出:
120/120 [==============================] - 7s 61ms/step
Loss = 7.773633257548014
Test Accuracy = 0.19166666666666668
利用已有模型进行测试:
model = load_model('ResNet50.h5')
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
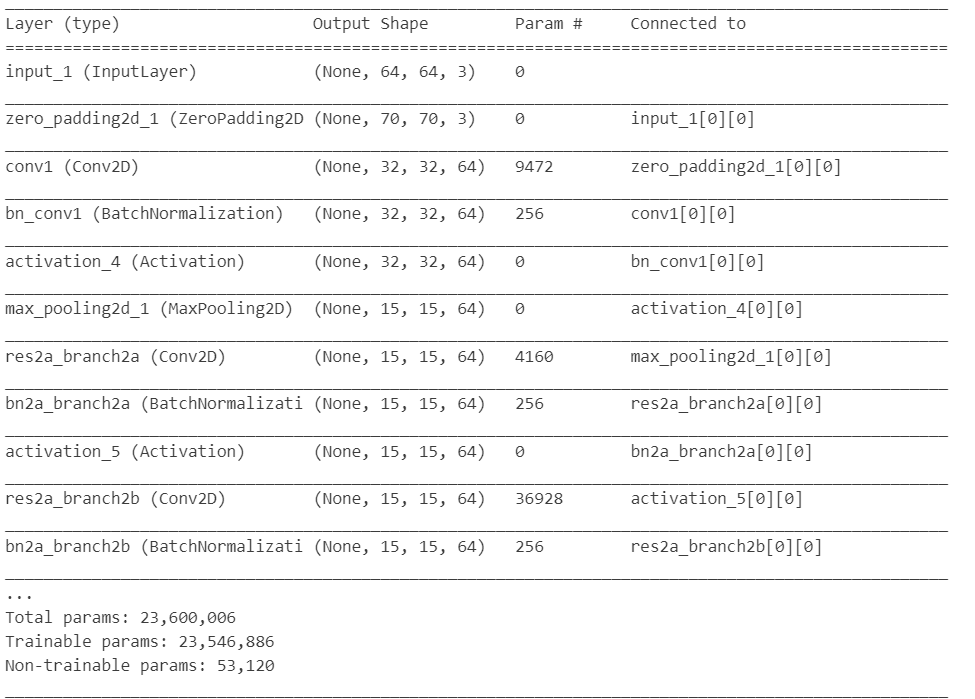
5.模型总结
ResNet50我们可以通过下述代码进行输出:
model.summary()
ResNet50的模型结构如下:
利用这段代码可以将模型结构进行图框输出:
plot_model(model, to_file='model.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
