每日计划
2023-12-17
- 学习感知机以及多层感知机原理,并通过代码进行实现
2023-12-18
- 学习深度学习计算(了解层与块的定义、自定义层进行参数管理)
- 了解卷积神经网络的图像卷积、填充步幅、maxpool
- 学习传统经典网络:LeNet
2023-12-19
- 学习现代卷积神经网络:VGG、AlexNet、GoogLeNet、NiN、BatchNorm(批次归一化,不算网络)、ResNet、DesnseNet
- 完成依据细菌光谱分类细菌的实验结果的整理和数据样例的归纳
2023-12-20
- 完成针对五种不同方法表格的数据汇总(SVM、RNN、KNN、CNN、MBAA-CNN)
- 学习现代循环神经网络(GRU、LSTM、、、)
2023-12-21~2023-12-22
- 阅读毕设文献,并撰写开题报告
2023-12-23(周六休息)
2023-12-24(半休息)
- 开题报告二修
- 模型介绍部分,把支持信息,重要正文区分好(等正式版出了再改,已提交所需)
2023-12-25(圣诞节)
- 形势与政策笔记
- 完善开题报告并交给师兄帮忙修改
看了爱乐之城重映,很喜欢《City of Stars》
2023-12-26(发烧)
- 结束开题报告撰写并提交
- overview先前学过的基础算法
- 研究毕设代码、为其配置运行环境并跑通
2023-12-27(发烧)
- 简单学习序列到序列生成模型(seq2seq)动手跟着视频实现,能理解多少是多少
- 简单了解束搜索
- 形势与政策大作业撰写+形势与政策课后习题
2023-12-28~2024-1-1(发烧休息)
2024-1-2
- 学习注意力机制并手敲一遍相关代码
2024-1-3~2024-1-4
- 跟着李沐精读一遍Transformer论文和手敲一遍代码
2024-1-5
- 读一遍师兄提供的基于Meta边界细化的鲁棒时间动作定位论文,整理出思维导图
- 汇总师兄提供的论文资料并整理好,确定BaseLine并安排下一步进度
2024-1-6~1-7
- 和师兄讨论顶刊思路并理一遍
- 阅读
ActionFormer,整理其文章内容 - 配置
ActionFormer运行环境并成功跑通代码
2024-1-8
- 修改并优化MBAA-CNN模型并重新运行
- 优化Github文档和相关代码
- 优化Github自己的Profile
2024-1-9
- 制作小组会PPT
- MBAA-CNN开会,整理文档
2024-1-10
- 制作小组会PPT的讲演稿,熟悉并理好论文的结构
- 阅读
Video Moment Retrieval With Noisy Labels,了解类别间和动作边界标注的噪声标签。
2024-1-11
- 开Visual Generation 小组会,了解到
Graph Information Bottleneck for Subgraph Recognition这篇论文不错 - 阅读
Refinement of Boundary Regression Using Uncertainty in Temporal Action Localization,大致了解边界回归问题 - 和邓老师讨论毕设开题任务(下一步需要通过文章进一步了解这个领域,然后整理这十篇文章的每篇的情况)
2024-1-12
- 整理十三篇文章的每篇的思想和解决的问题(加上
video grounding领域结合大模型的文章、以及NIPS和ICLR上偏数学性的causal reasoning)
2024-1-13~2024-1-14
-
汇总调研报告制作汇报PPT并给老师进行汇报
发现的问题:(后面还需继续解决)
-
报告格式不好,调研报告开头要有汇总式的结论,列清楚每种方法的优缺点,要有图。
-
对这个领域还不够了解,读最新论文的时候要思考有什么可以借鉴的地方套过来用。
-
可以尝试结合多层Transformer的特征金字塔来对视频动作定位过程中筛选的输入特征进行编码操作,融入到HR-Pro方法。
-
-
2024-1-15
- 继续调研并完善调研报告,
2024-1-16
- 毕设思路整理 1.多层Transformer 2.结合线索树聚合 (今天阅读相关论文了解其基本机理) 3.可以尝试使用预训练的大模型辅助监督
2024-1-17
- 整理小组会PPT进行汇报,结果是上述毕设思路不太可行
- 考虑融合TriDet论文的TriDet模块,
- 参考有临近样本相似一致思想文章
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation用于HR-Pro伪类标标记
2024-1-18~2024-1-21
- 融合TriDet的模块SGP,替换掉SA部分,目前跑通但无效果
- 不清楚如何利用临近样本一致思想来修改我的代码,方案暂且不通
- 调参,基于已有的多层注意力机制效果高于baseline,如何提高一个点?
- 参加MBAA-CNN小组会,进一步完善论文措辞,下一步定终稿
2024-1-22
- 再次阅读TriDet和SFDA,考虑如何修改代码能让数据特征合理的被输入和输出
- 筹备制作小组会讲演PPT,初步想法汇报这两篇论文和我利用多层注意力及特征计算加权平均对于BaseLine的 提高。
- 通过阅读代码,发现Reliabilty_Aware_Block返回的attn权重没用,只关心处理后的特征
2024-1-23
- 尝试融合SGP和MSA进行多层次融合,调试代码
2024-1-24
- 调试代码,发现可行性不是很高,准备小组会和老师、师兄进行讨论新的方案想法
- 完善小组会PPT,把疑问点良好的表达出来
2024-1-25
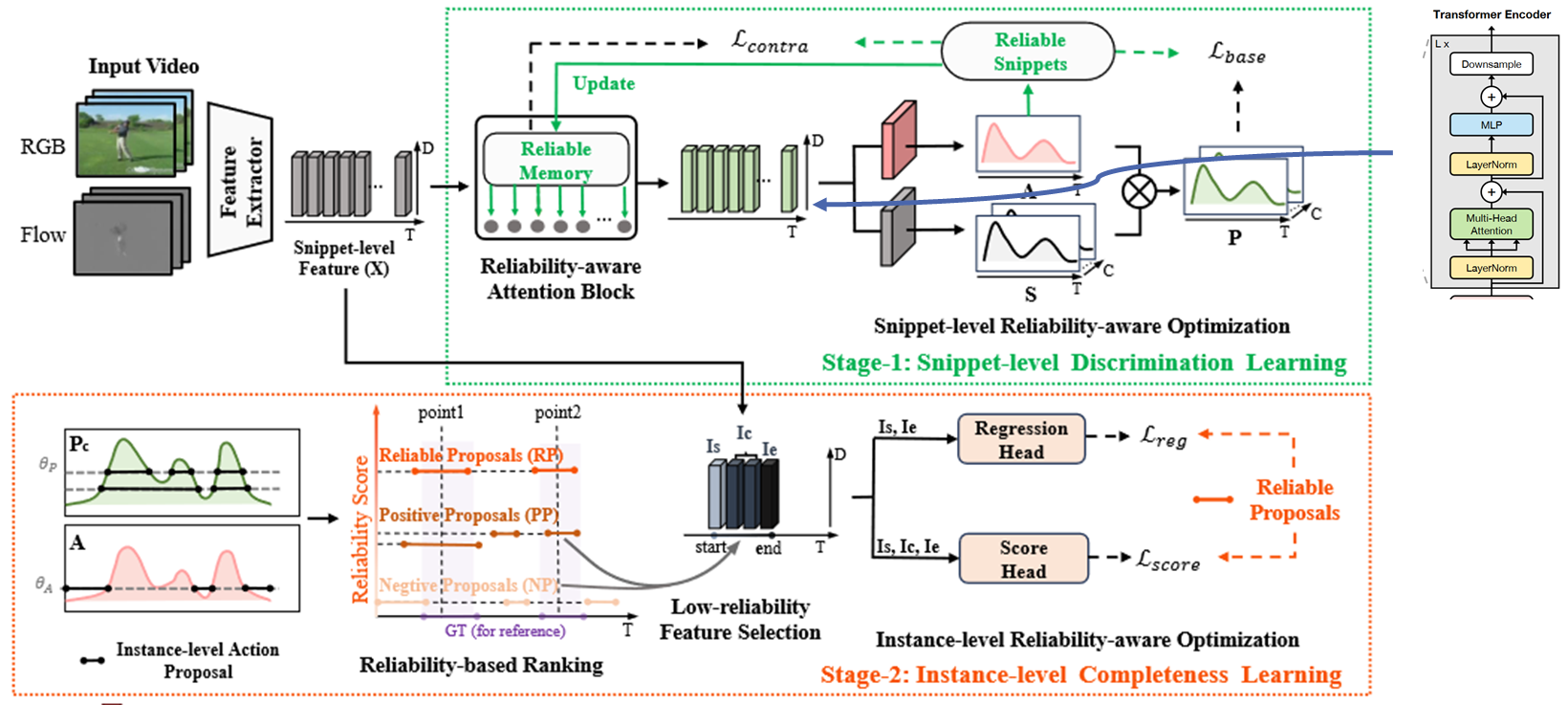
- 研究如何把实例级片段生成的可靠性建议进行完善:
通过咨询师兄,已有思路:
- 伪类标基本范式:先通过那个点监督的帧的信息进行分类,得到那个每个类的分类score(横轴为T),再根据这个score打伪类标。
- 思路1:针对实例级片段前面的 proposal生成,查找最新的伪标签生成方法,改进伪标签(pseudo-labels)的生成。
- 思路2:合在一起训练 或者变成交替优化的,阶段1用的伪标签是直根据预定义阈值(预定义阈值可以试试自适应学一个?每个类不一样)生成的 阶段2实际上是用RP做ground truth。
- 思路3:多模态
Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization - 思路4:最后直接回归边界 不用nms。(不可行,但是调整NMS高斯权重系数可以提升点)
- 健身
2024-1-26
- 接着按照上面的思路看论文研究思路。
2024-1-27~2024-1-29
Agent Attention阅读,借鉴其将softmax注意力和线性注意力结合的注意力(Agent·)- 一个思路,就是把这两个阶段合在一起训练或者变成交替优化的。阶段1用的伪标签是直根据预定义阈值生成的,阶段2实际上是用RP做ground truth。然后阶段一可以用一个方法针对不同类自适应学习预定义阈值。
2024-1-30
- 查阅自适应学习预定义阈值的方法,做好调研
- 做小组会PPT(本周主要讨论两个角度:1、如何将片段级和实例级交替优化? 2、(伪片段)什么方法可以针对不同类自适应学习预定义阈值)
2024-1-31~2024-2-20
休息为主
2024-2-21
- 修改HR-Pro代码,调试参数,尝试融合AgentAttention模块
2024-2-22
-
尝试融合AgentAttention四种类型的模块,测试可行性(失败,GPU显存不足,模型复杂度可能过高)
-
调试参数(先前的MultiSGP模块)(失败)
-
过一遍MBAA论文,勘误
-
一个想法:
Base: Snippet-level利用预设定的阈值->生成粗略的(伪动作片段和伪背景片段)提案的置信度分数和边界 基于点注释的实例级提案生成器->可靠性提案(RP)-> Instance-level利用RP生成完善的伪动作片段和伪背景片段来优化。
可不可以把第二部生成的RP结果来为第一步的Snippet-level不同片段阈值的生成提供指导。
2024-2-23
- 融合AgentAttention四种类型的模块在AutoDL上测试(成功)
- 整理过一遍师兄鲁棒性项目,先要知道要做出什么效果(类内噪声标签和类间噪声标签结合)>
2024-2-24(周六休息)
去永兴坊和城墙下逛灯会,去大唐西市转了一圈发现没啥好玩的。
2024-2-25
- 整理做出小组会学期报告PPT,确定下一阶段目标
- 看师兄的鲁棒性项目
2024-2-26
-
开小组会学期汇报
-
交替优化初尝试
方案:基于损失反馈的交替优化 初始化阶段:加载两个模型(S_Model和I_Model),并为它们准备各自的数据加载器和优化器。 交替优化循环:设置一个外循环,每次循环首先进行Snippet-level优化,然后进行Instance-level优化。每个阶段的优化基于损失值的反馈来决定是否继续在当前阶段优化或者切换到另一个阶段。 损失值反馈:如果当前阶段连续几次迭代损失下降不明显,则切换到另一个阶段。 终止条件:可以基于最大迭代次数或者两阶段优化的综合改进情况来设置。
2024-2-27
- 交替优化进一步完善,调试参数观察结果
- 思考毕设论文的写作结构和参考的论文结构
2024-2-28
作者:时间旅客
链接:https://www.zhihu.com/question/25097993/answer/3410497378
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.不管什么模型,先在一个较小的训练集上train和test,看看它能不能过拟合。如果不能过拟合,可能是学习率太大,或者代码写错了。先调小学习率试一下,如果还不行就去检查代码,先看dataloader输出的数据对不对,再看模型每一步的size是否符合自己期待。
2.看train/eval的loss曲线,正常的情况应该是train loss呈log状一直下降最后趋于稳定,eval loss开始时一直下降到某一个epoch之后开始趋于稳定或开始上升,这时候可以用early stopping保存eval loss最低的那个模型。如果loss曲线非常不正常,很有可能是数据处理出了问题,比如label对应错了,回去检查代码。
3.不要一开始就用大数据集,先在一个大概2w训练集,2k测试集的小数据集上调参。
4.尽量不要自己从头搭架子(新手和半新手)。找一个已经明确没有bug能跑通的其它任务的架子,在它的基础上修改。否则debug过程非常艰难,因为有时候是版本迭代产生的问题,修改起来很麻烦。
5.优化器优先用adam,学习率设1e-3或1e-4,再试Radam(LiyuanLucasLiu/RAdam)。不推荐sgdm,因为很慢。
6.lrscheduler用torch.optim.lr_scheduler.CosineAnnealingLR,T_max设32或64,几个任务上试效果都不错。(用这个lr_scheduler加上adam系的optimizer基本就不用怎么调学习率了)
7.有一些任务(尤其是有RNN的)要做梯度裁剪,torch.nn.utils.clip_grad_norm。
8.参数初始化,lstm的h用orthogonal,其它用he或xavier。
9.激活函数用relu一般就够了,也可以试试leaky relu。
10.batchnorm和dropout可以试,放的位置很重要。优先尝试放在最后输出层之前,以及embedding层之后。RNN可以试layer_norm。有些任务上加了这些层可能会有负作用。
11.metric learning中先试标label的分类方法。然后可以用triplet loss,margin这个参数的设置很重要。
12.batchsize设置小一点通常会有一些提升,某些任务batchsize设成1有奇效。
13.embedding层的embedsize可以小一些(64 or 128),之后LSTM或CNN的hiddensize要稍微大一些(256 or 512)。(ALBERT论文里面大概也是这个意思)
14.模型方面,可以先用2或3层LSTM试一下,通常效果都不错。
15.weight decay可以试一下,我一般用1e-4。
16.有CNN的地方就用shortcut。CNN层数加到某一个值之后对结果影响就不大了,这个值作为参数可以调一下。17.GRU和LSTM在大部分任务上效果差不多。
18.看论文时候不要全信,能复现的尽量复现一下,许多论文都会做低baseline,但实际使用时很多baseline效果很不错。
19.对于大多数任务,数据比模型重要。面对新任务时先分析数据,再根据数据设计模型,并决定各个参数。例如nlp有些任务中的padding长度,通常需要达到数据集的90%以上,可用pandas的describe函数进行分析。
2024-2-29
小组会的问题:
- 关于师兄的基于元边界细化的鲁棒TAL任务,重新理一下,如何加入类间噪声
- 关于TAL相关论文往哪个大类看?还是都看看比较好?(视频理解?多模态?视觉和语言?视频检索?目标检测?)
- 关于毕设下一阶段针对交替优化有无好的解决方案?
新任务
- 交替优化可以考虑最基础GAN的方法
- 找最基础的图像生成扩散模型的代码
2024-3-1~2024-3-3
主要对latent-diffusion环境进行配置,并且跑通原作者对于ImageNet数据集的训练LDM代码。
下一步主要思考如何去掉encoder和decoder,直接用视频的特征进行训练,跑通即可
- 准备小组会PPT进行进展汇报,分享两篇论文
2024-3-4~2024-3-13
手术养病休息
2024-3-14
- latent-diffusion针对ddpm.py文件进行修改,确定encoder和decoder位置和输出特征的位置。
- 规划中期答辩思路和PPT制作
2024-3-15~2024-3-19
- 准备中期答辩相关材料(PPT、中期报告、八篇周记)
- Debug师兄项目的测试代码,目前已经跑通,需要进一步研究
- 小组会PPT
2024-3-20
-
老师快递小组会带过去
-
讨论MM代码
小组会需要注意的是:
1.毕设既然做不下去,那么后面要抓紧时间推进AAAI噪声标签的项目。
2024-3-27
- 和师兄讨论后目前AAAI第一阶段思路总结:
1.先按照从经典方法到最新的方法(G-TAD、Proposal Based Method(有锚点)、actionformer(无锚)、top-K Attention)分别加入相同的高斯噪声扰动,看看谁的鲁棒性更好一些?接着看加入12种外界corrptions后谁的鲁棒性更强一些?
2.综合来看找到一种方法,然后去分析这个鲁棒性更好(猜测就是transformer结构)的方法,内部哪个模块哪个机制导致模型鲁棒性这么强?
3.然后顺着这个路线基于tansformer结构,去做一种鲁棒性更好的框架,来适应开放场景下的不同噪声(类别内噪声边界问题、类别间噪声标签错误问题、open world下的扰动噪声问题),从而达到更好的鲁棒性。
- 魏老师提供的思路:
1.先进行类别间的噪声标签的修正,然后进行类别内的噪声边界细化修正。(不清楚如何)
- 毕业设计要抓紧安排找时间写完,方便后续工作安排。
- GTAD: https://github.com/frostinassiky/gtad
- Proposal Based: https://github.com/RenHuan1999/CVPR2023_P-MIL
- ActionFormer: https://github.com/happyharrycn/actionformer_release
- Top-k: https://github.com/ag1988/top_k_attention(https://github.com/Roytsai27/Financial-GraphAttention)
2024-3-28~2024-4-3
- 针对actionformer、g-tad、P-MIL、HR-Pro进行动作边界加噪和动作类别加噪研究
- MDMT多目标识别代码跑通并可视化结果
- MBAA-CNN润色加小修(找合适时间进行讨论)(1、ROC曲线结果别太完美;2、区别四种算法是传统机器学习还是现代深度学习)
- 日常小项目接单
2024-4-4~2024-4-5(清明节休息)
2024-4-6
- 完善actionformer、P-MIL、加噪实验
- (HCP、GOD、BOLD500、NAD)把每个数据集是怎么采集的、怎么处理的、每个数据都代表什么意思,搞清楚
2024-4-7
- 嘉华师兄提到的迭代优化思想(ACL2023-Generating Structed Pseudo Labels for Noise-Resistant Zero-Shot Video Sentence Localization)figure4中的迭代优化可以结合co-teaching,相当于一边co-teaching,一边修正。
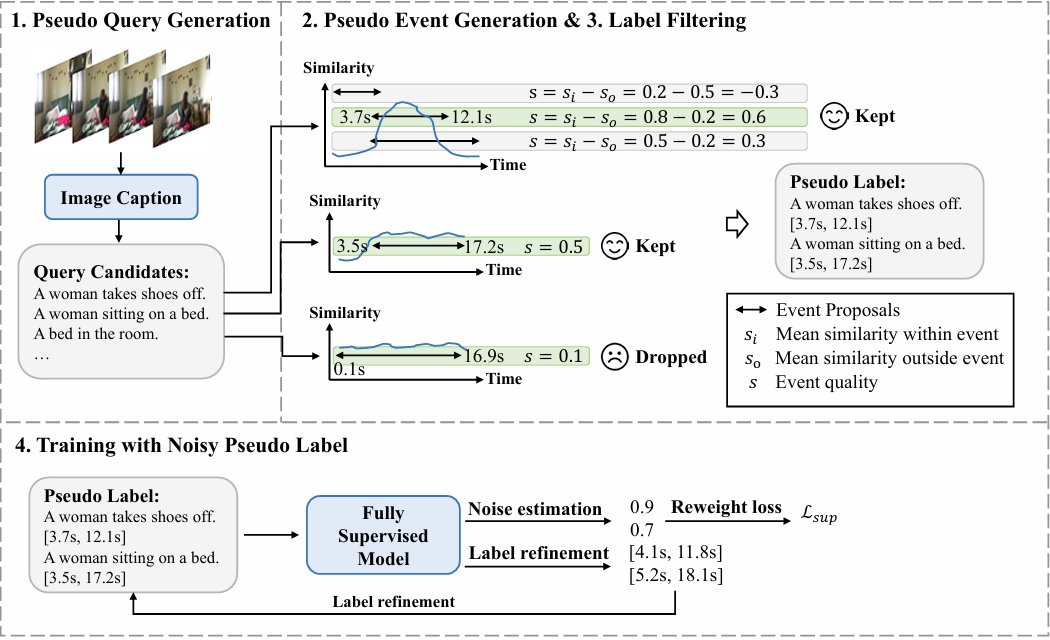
- 噪声边界噪声加噪的时候不要给test数据进行边界和类间加噪。
- 接单pytorch训练yolo
- 脑电数据集调研信息收集
2024-4-8
- 继续完善脑电数据集调研信息(√)
- 了解一下这个竞赛(https://mp.weixin.qq.com/s/_epZnE2QrSyw9wNzcTudoQ),并组队讨论一下(√)
- 看昨天师兄推荐的迭代优化思想的文章
2024-4-9
-
以后要按时来实验室打卡,不能早退晚到(√)
-
-
加噪边界和类别噪声检查是不是不小心加到测试集上了(√)
-
魏老师的MDMT2.6部分撰写
-
继续在脑机FRMI数据集GOD、BOLD5000、NSD处理原始数据的代码和论文(√)
-
完成了计图竞赛的环境配置和第一个任务(热身赛),赛题1数据集和环境已经配置完毕并可以正常运行
清单汇总:
- 毕业设计论文撰写※※※※
- 对于tridet和actionformer进行类内边界加噪实验和类间标签加噪实验,对比不同noise的性能下降情况
- 研读师兄推荐的迭代优化文章,可以结合co-teaching,相当于一边co-teaching,一边修正噪声损失。※※
- 脑机FRMI数据集GOD、BOLD5000、NSD处理原始数据的代码和论文和数据集
- 计图竞赛的环境配置和第一个任务(热身赛),赛题1数据集和环境已经配置完毕并可以正常运行
- 魏老师MDMT代码复现(√)+对应2.6章节撰写(针对多目标任务下的特性识别(MDMT数据集,身份关联))
- MBAA-CNN论文定稿最终修改(放在周四周五再慢慢看)
- 启元项目数据清洗和代码论文收集
2024-4-10~4-11
完成了上述的MBAA-CNN、2.6章节撰写、帮同学收集文献杂活、anet1.3类内边界噪声加噪实验
2024-4-12
- 对anet1.3的类别容易混淆的种类进行分组,进行类间噪声测试
- 完成2.6章节的撰写并画完图
2024-4-13
- 写毕设(写了一个框架)
2024-4-14周末、2024-4-15
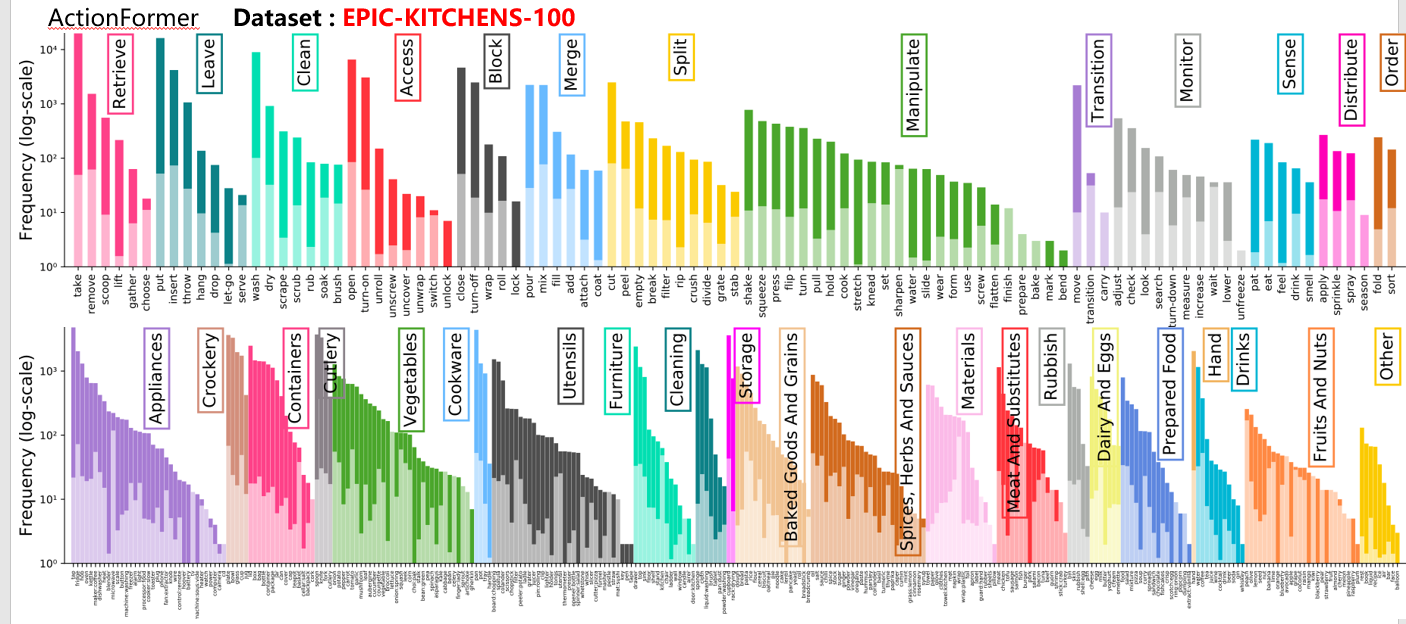
- 完成针对EPIC-KITCHENS-100数据集的边界和类别加噪实验,完成所有baseline的实验
- 完成MDMT2.6章节撰写并结束画图
- 帮师兄实现https://mask-cond-video-diffusion.github.io/:
1、跑通Stochastic Moving MNIST这个实验
2、看看这篇论文的框图 就直接是有个历史帧作为条件输入 预测未来帧,再帮我看看,进行video prediction任务时,条件输入是啥(是不是历史帧),在代码哪部分?
解决思路:

- 和师兄敲定下一阶段AAAI思路(两个:1、根据师兄已有元学习基础上进行完善,先把Adamw跑通,解决这个bug,提升效果。后面针对类别噪声再加入类别模块来处理。2、直接自己做一个基于上面提到过的迭代优化和coteaching模块【分类块】结合的降低类别和边界噪声的模块)
2024-4-16
- 尝试解决上述提到过的思路1问题
2024-4-17~2024-4-19
- 思路1跑通但存在结果不好的问题,重新检查
- 毕业论文撰写,写出初稿一遍,明天接着过一遍检查一下
2024-4-20~2024-4-24
- 毕设二修再让胥师兄帮忙看一遍准备进行三修
- 针对计图,可以使用LLama对类别进行扩写,主要从clip提示进行入手(目前做的是先用图像文本预训练模型和文本总结生成每个类图片的caption然后进行提取文本特征,增强其泛化性)
- anet1.3类别噪声代码检查(解决不了)
2024-4-25~2024-4-26
- 三修毕业设计论文结束
- 计图下一阶段我的任务是对class的caption生成完整的对应描述,针对特征融合进一步优化
- 二昆老师任务书
- MDMT稍微改一下计划书,主要注意一下图片表格
2024-4-27~2024-4-28
- 帮师兄修改代码然后跑通,然后继续沟通下一步操作(修改了长期记忆压缩模块)
- MDMT稍微改一下计划书,主要注意一下图片表格
2024-5-5~2024-5-9
- 接单智科作业(400R)
- 毕设小导师帮忙修改+盲审材料准备并反复检查,提交!
- 本科生综合测评材料准备并提交,试着看看能不能评一下优秀毕业生
师兄TSGV代码任务:
-
long_memories压缩编码模块修改(√)
-
在跑TSGV的MAD和TACOS数据集baseline(马上开始)
/data1/mcy/code/MM2025/TSGVs-MM2023-for-tacos/TSGVs-MM2023-main-ljh/目录下运行: nohup bash ./tools/dist_train.sh configs/tpn/benchmark/tacos_mtl_16_tpn_dec1_rnn_dot_s8_l64_b8_64_kd02.py 4 --work-dir /data1/mcy/code/MM2025/TSGVs-MM2023-main-ljh/work_dirs/tacos_ljh --validate --test-best & ###################################### /data1/mcy/code/MM2025/TSGVs-MM2023-for-tacos/TSGVs-MM2023-baseline/目录下运行: nohup bash ./tools/dist_train.sh configs/tpn/benchmark/tacos_mtl_16_tpn_dec1_rnn_dot_s8_l64_b8_64_kd02.py 4 --work-dir /data1/mcy/code/MM2025/TSGVs-MM2023-main-ljh/work_dirs/tacos_baseline --validate --test-best & -
future_memory_length进行消融实验(8,16,128的消融正在跑,32,64没跑TACOS数据集准备好(basline和ljh预备跑)MAD数据集正在下载(有问题?))
2024-5-10~2024-5-13
- 针对GTfuture和原始修改后的消融实验跑完
- 小语种五种语种
- 注册openreviewer,后续neurips投稿需要
- TSGV的MAD和TACOS数据集baseline代码对比实验跑完
- 思考类别加边界噪声标签通过什么方法来改进是很好的创新点?
- 毕设答辩PPT制作
归档材料整理顺序:
1、封面 √
2、诚信声明书
3、毕设任务书 √
4、毕设工作计划 √
5、开题报告 √
6、中期报告 √(时间还没写好)
7、中期检查表 √
8、指导教师评定意见表 √
9、评阅人评定意见表 √
10、毕设成绩登记表
11、摘要、正文 √
12、盲审意见书 √
13、查重报告 √
14、外文资料翻译 √
15、毕设指导情况登记表
2024-5-14~2024-5-15
- 毕设答辩PPT制作完成
- 针对TSGV代码对compressor、future_memories和transformer decoder三个部分进行消融实验(18个小时跑完,正在跑)
- 小组会
2024-5-16
AAAI思路
动作边界噪声处理改进:
使用Transformers
a. Temporal Transformers: 利用时序Transformers(如TimeSformer)捕捉长时间跨度的视频信息,从而提高边界定位的精度。
实现建议:
- 采用预训练的时序Transformers模型,进行微调。
- 结合元学习和边界能量损失,进一步优化模型。
b. Vision Transformers (ViT): 利用Vision Transformers(ViT)提取视频帧的全局特征,增强模型对边界的理解。
实现建议:
- 将视频分为小块(patch),使用ViT提取每个块的特征。
- 将提取的特征输入到时序Transformers中进行边界定位。
类别名称噪声处理改进:
使用Vision-Language Models
a. CLIP (Contrastive Language–Image Pre-training): 利用CLIP模型,将图像和文本(类别名称)嵌入到同一个特征空间,从而减少类别噪声的影响。
具体做法:
- 使用CLIP模型提取视频帧和类别名称的特征。
- 采用基于特征空间的距离度量进行类别预测,减少类别噪声对模型的影响。
使用Noisy Student Training
a. Noisy Student Training: 结合Noisy Student Training方法,通过生成伪标签和学生模型迭代训练,增强模型对类别噪声的鲁棒性。
实现建议:
- 训练一个教师模型生成伪标签。
- 训练学生模型,并在训练过程中加入噪声,提高模型的泛化能力。
x——————————————————————————x
针对上述提到的用VIT和CLIP,可以在I3D特征基础上进行融合。
2024-5-17~2024-5-20
- 毕设最终答辩PPT制作
- 预答辩
2024-5-21~2024-6-1
- 毕业设计答辩
- 毕业设计评优ppt和论文准备
- 毕业设计归档材料整理汇总(归档材料,毕业论文终稿,关键词,查重报告)
- 启元项目+lxy师兄
2024-6-2~2024-6-14
- 小语种项目筹集(数据集调研+汇总下载)
- 医学数据集(眼底、X光、CT、病理)2D图像收集整理(要针对不同来源的数据库针对同一疾病的分类任务,标签基本要一样)
- AAAI2025思路重新整理,思考如何写好故事。
要解决的问题:
针对原始数据集,由于人工手动注释的固有主观性,可能包含嘈杂的动作边界标签+嘈杂的动作类别标签。这导致 TAL 模型在训练期间学习不准确的动作边界和类别,损害定位性能。
动作边界噪声:数据集的人工标注与真实情况有误差,时间上有错开的偏移。
动作类别噪声:数据集的人工标注与真实情况有误差,相似的动作可能标注错误。
想要实现的:
综合一个综合噪声鲁棒性细化模块,既能解决开放场景下数据集获取过程中的时间信息被破坏情况(模糊、过曝、遮挡、丢包等),又可以解决针对数据集内部人工手动注释存在的嘈杂动作边界标签+嘈杂动作类别标签构成的混合噪声。
思路:
针对视频中的时间信息被破坏情况,可以直接使用CVPR24的工作,在此基础上加上考虑降低嘈杂的动作边界标签+嘈杂的动作类别标签对TAL定位任务的影响。
2024-6-15~2024-6-21
- 毕业相关事项手续材料收尾
2024-6-22~2024-6-26
- 医学影响数据集进一步汇总并简单预处理(train:test=7:3)发给师兄
- aaai25思路被否定,不太行,不知道下一步该怎么办
- 期末周复习冲刺矩阵论
- 看二昆老师给的医学影像数据集蒸馏相关的文章进行学习