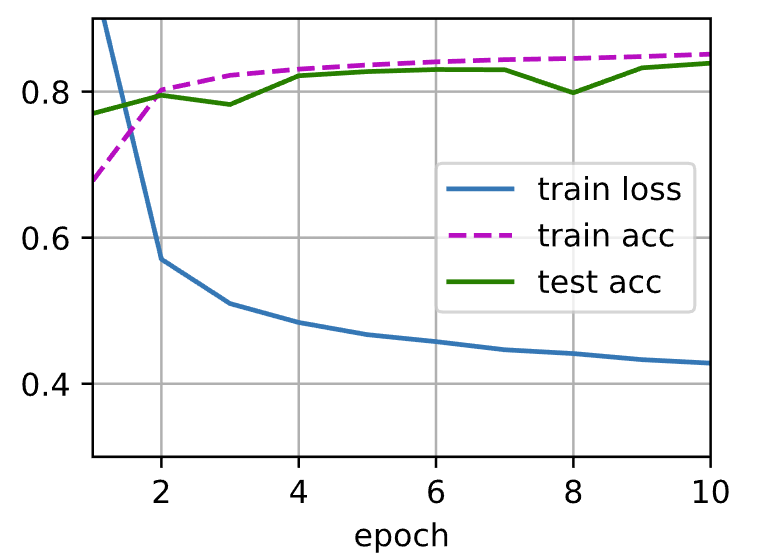
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import torch
from torch import nn
from d2l import torch as d2l
from d2l import util
num_inputs,num_outputs,num_hiddens = 784,10,256
W1 = nn.Parameter(
torch.randn(num_hiddens,num_hiddens,requires_grad=True))
b1 = nn.Parameter(torch.zeros(num_hiddens,requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True)*0.01)
b2 = nn.Parameter(torch.zeros(num_outputs,requires_grad=True))
params = [W1,b1,W2,b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X,a)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.01)
def net(X):
X = X.reshape((-1,num_inputs))
H = relu(X @ W1 + b1)
return (H @ W2 + b2)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.Linear(256,10)
)
net.apply(init_weights)
batch_size, lr, num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss(reduction='none')
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
updater = torch.optim.SGD(net.parameters(),lr=lr)
util.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater)
|