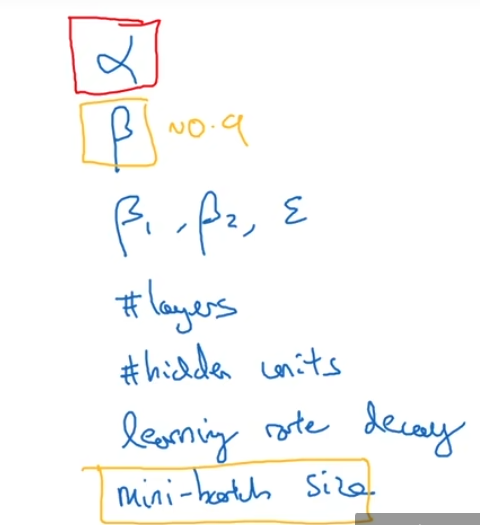
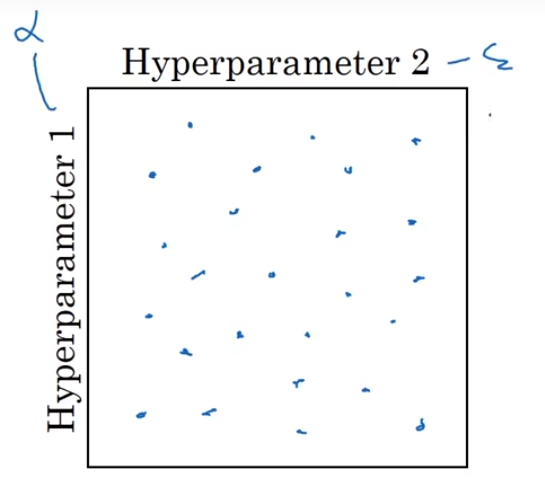
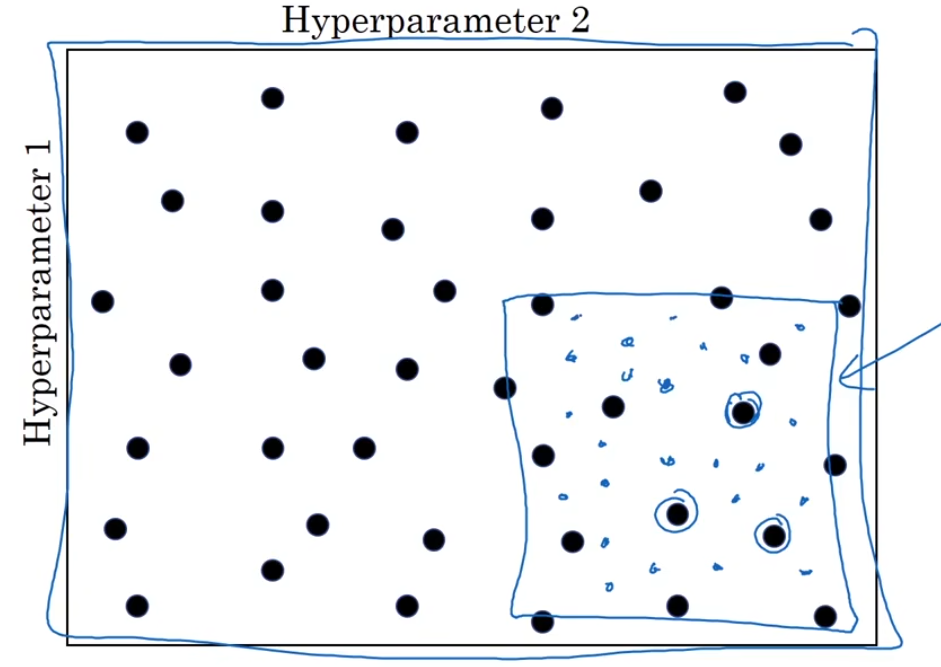
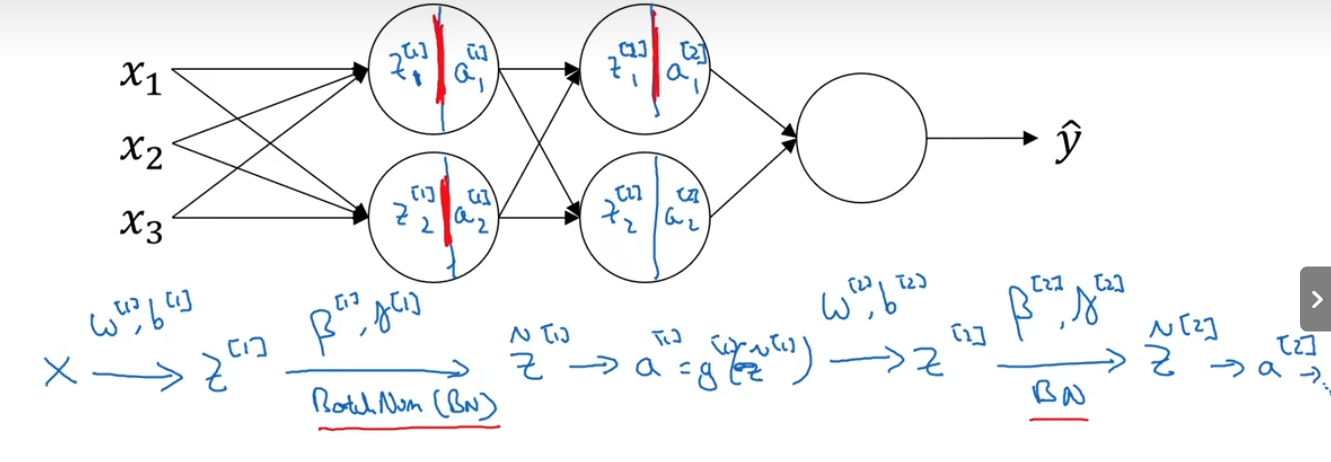
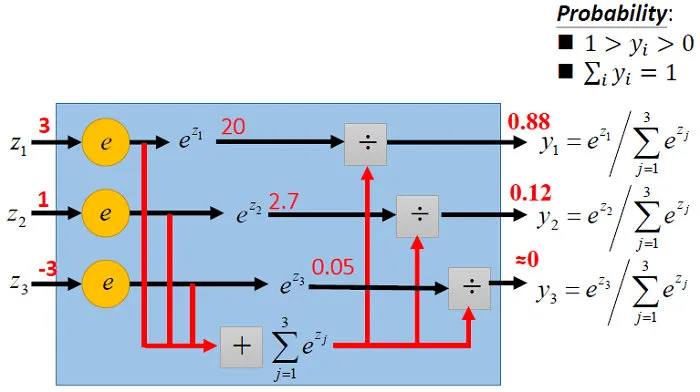
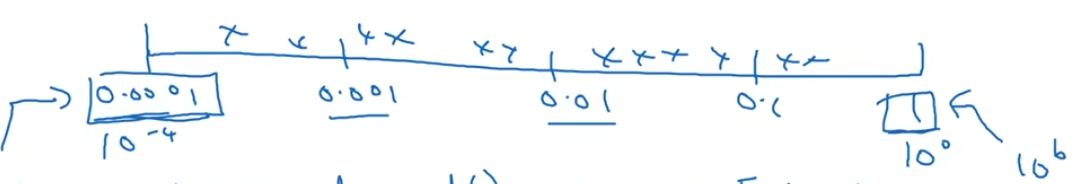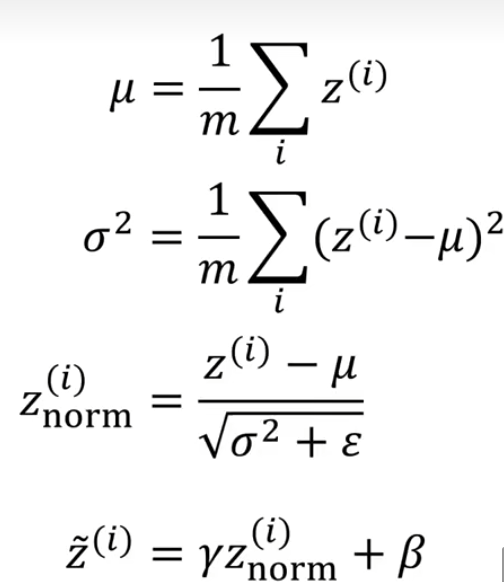1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| def load_dataset(file_path):
dataMat = []
labelMat = []
fr = open(file_path)
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
def train(data_arr, label_arr, n_class, iters = 1000, alpha = 0.1, lam = 0.01):
'''
@description: softmax 训练函数
@param {type}
@return: theta 参数
'''
n_samples, n_features = data_arr.shape
n_classes = n_class
weights = np.random.rand(n_class, n_features)
all_loss = list()
y_one_hot = one_hot(label_arr, n_samples, n_classes)
for i in range(iters):
scores = np.dot(data_arr, weights.T)
probs = softmax(scores)
loss = - (1.0 / n_samples) * np.sum(y_one_hot * np.log(probs))
all_loss.append(loss)
dw = -(1.0 / n_samples) * np.dot((y_one_hot - probs).T, data_arr) + lam * weights
dw[:,0] = dw[:,0] - lam * weights[:,0]
weights = weights - alpha * dw
return weights, all_loss
def softmax(scores):
sum_exp = np.sum(np.exp(scores), axis = 1,keepdims = True)
softmax = np.exp(scores) / sum_exp
return softmax
def one_hot(label_arr, n_samples, n_classes):
one_hot = np.zeros((n_samples, n_classes))
one_hot[np.arange(n_samples), label_arr.T] = 1
return one_hot
def predict(test_dataset, label_arr, weights):
scores = np.dot(test_dataset, weights.T)
probs = softmax(scores)
return np.argmax(probs, axis=1).reshape((-1,1))
if __name__ == "__main__":
data_arr, label_arr = load_dataset('train_dataset.txt')
data_arr = np.array(data_arr)
label_arr = np.array(label_arr).reshape((-1,1))
weights, all_loss = train(data_arr, label_arr, n_class = 4)
test_data_arr, test_label_arr = load_dataset('test_dataset.txt')
test_data_arr = np.array(test_data_arr)
test_label_arr = np.array(test_label_arr).reshape((-1,1))
n_test_samples = test_data_arr.shape[0]
y_predict = predict(test_data_arr, test_label_arr, weights)
accuray = np.sum(y_predict == test_label_arr) / n_test_samples
print(accuray)
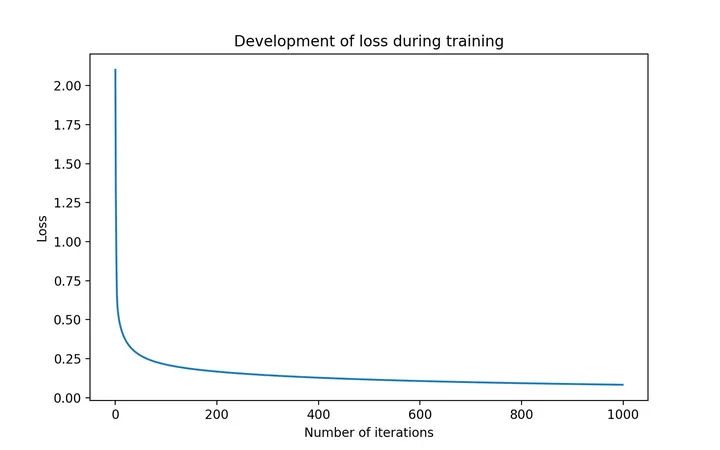
fig = plt.figure(figsize=(8,5))
plt.plot(np.arange(1000), all_loss)
plt.title("Development of loss during training")
plt.xlabel("Number of iterations")
plt.ylabel("Loss")
plt.show()
|