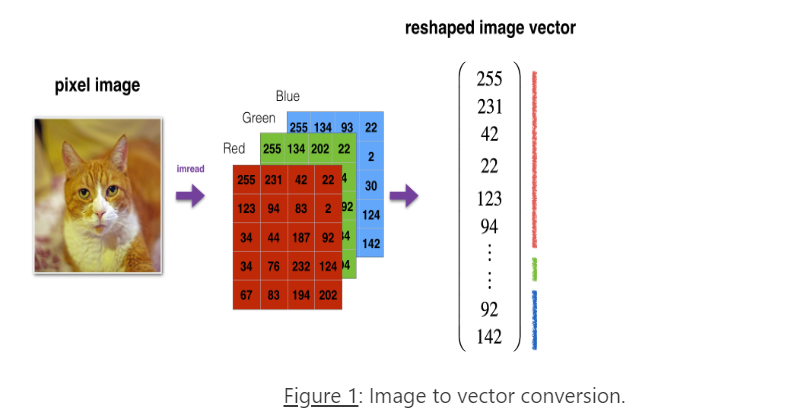
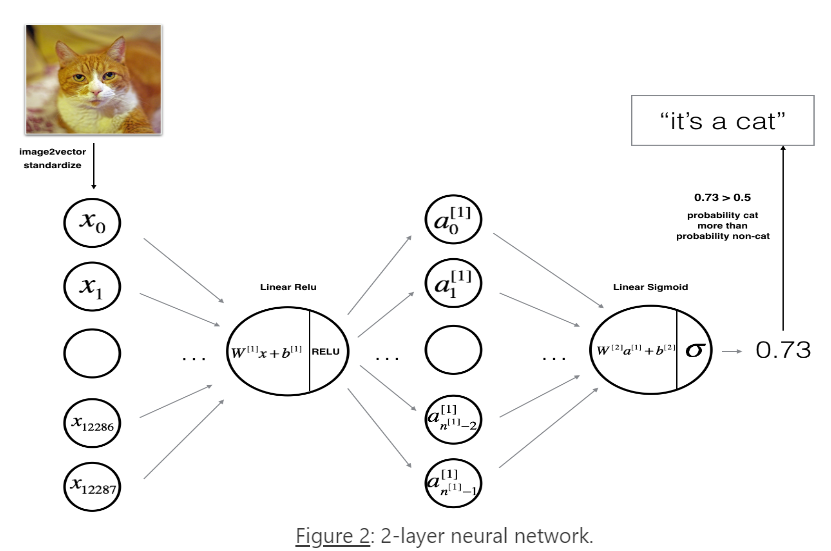
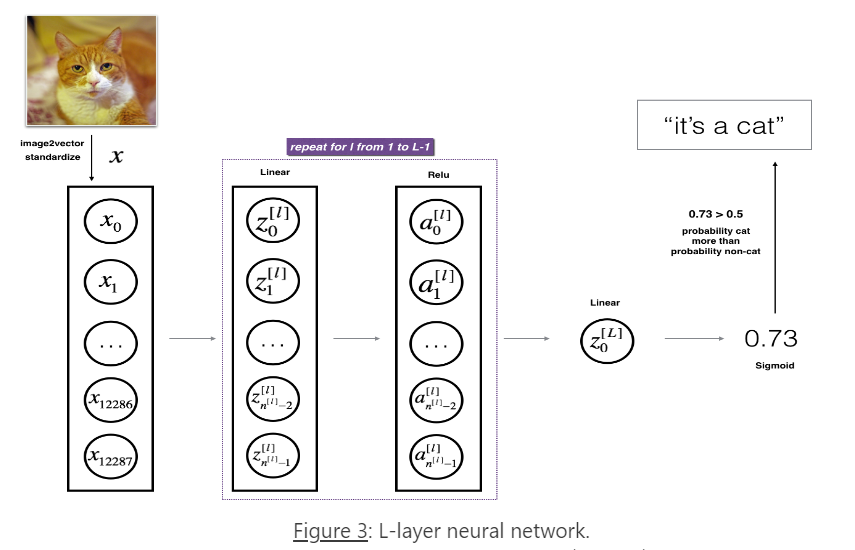
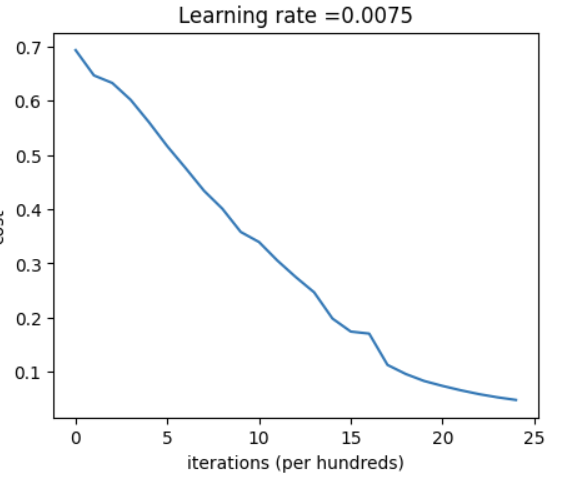
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
def initialize_parameters(n_x,n_h,n_y):
np.random.seed(1)
W1 = np.random.randn(n_h,n_x)*0.01
b1 = np.zeros((n_h,1))
W2 = np.random.randn(n_y,n_h)*0.01
b2 = np.zeros((n_y,1))
assert((n_h, n_x) == W1.shape)
assert((n_h, 1) == b1.shape)
assert((n_y, n_h) == W2.shape)
assert((n_y, 1) == b2.shape)
parameters = {
"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2
}
return parameters
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert(A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
def compute_cost(AL,Y):
m = Y.shape[1]
cost = -(np.dot(np.log(AL), Y.T) + np.dot(np.log(1 - AL), (1 - Y).T)) / (1.0 * m)
cost = np.squeeze(cost)
assert(cost.shape==())
return cost
def linear_activation_backward(dA, cache, activation):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2
for i in range(1, L + 1):
parameters["W" + str(i)] -= learning_rate * grads["dW" + str(i)]
parameters["b" + str(i)] -= learning_rate * grads["db" + str(i)]
return parameters
|