
最近阅读到这篇论文,对于里面的调种子的方法比较感兴趣,简单记录一下阅读过程中的一些发现以及一些思考。
首先先说结论:即使方差不是很大,也很容易找到一个比平均值表现好得多或差得多的异常值。这意味着如果计算量充足并且研究者对于自己的研究足够负责,那么最好探究一下因为随机种子设置、数据集划分等随即来源对于实验结果的影响,最终通过类似平均值、均值、方差、标准差、最值等数据形式展现。
问题描述
这是一篇论述通过设置torch.manual seed(3407)随机种子对于模型最终结果影响的实验性文章,作者通过大量实验选择出来一类可以影响模型精度的种子。在CIFAR10数据集上,作者探究了一万多个随机种子,同时也利用预训练模型在ImageNet大数据集上进行实验。
整篇文章围绕着这三个问题展开的:
- 随机种子的不同导致的模型结果分布是怎样的?
- 是否存在黑天鹅事件,也就是存在效果明显不同的随机种子?
- 在更大的数据集上进行预训练是否可以减少由选择种子引起的差异性?
实验设置
由于这只是一个简单的实验,并不是想要得到模型最好的结果,因此作者仅尝试在V100 GPU上进行实验,GPU时间限制为1000小时。(作为实验来讲,算力还是很充足的😄)
CIFAR 10: 在CIFAR 10数据集上,作者选取了10000个随机种子,每个随机种子利用30s的时间来训练和测试,总耗时将近83h。模型架构采用的是9层ResNet,优化器是SGD。为了保证部分实验中,模型是接近收敛的,因此作者对其中500次的结果训练时长延迟至1分钟。最后,总算力消耗为90h的V100 GPU运行时间。
ImageNet: 在ImageNet大型数据集上难以快速进行实验,因此作者使用预训练好的网络,然后仅仅对于最后一层分类层进行初始化并从头训练。每次实验模型训练时间为2h,测试50s。最终总耗时440h的V100 GPU运行时间。
实验缺陷:
作者通过实验表面,以上这种实验设置存在如下缺陷:
- 实验中,模型结果并不是SOTA(由于运行时间限制导致,可能训练时间进一步增加可以得到更好的结果)
- 在ImageNet数据集上,作者使用的是预训练模型,仅对最后一层网络进行训练,所以最终的结果只能说明与最后一层的训练和优化有关(而不是整个模型)。
问题解决
1、随机种子的不同导致的模型结果分布是怎样的?
针对第一个问题,作者首先在CIFAR 10上对500个不同的种子进行训练,得到如下结果图:(视线为均值,深红色区域对应一个标准差,浅红色对应最大值和最小值)
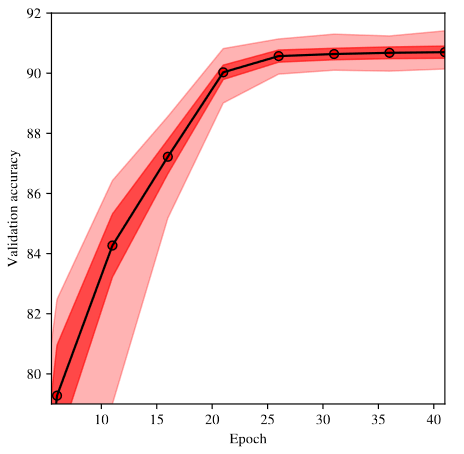
作者发现:
1. 模型在25个epoch后准确率就不增加了,说明训练收敛了。然而,准确率的标准差并没有收敛(红色区域并没有变小),说明训练更久不会减少随机种子带来的差异。
- 模型准确率大多集中在90.5%至90.1%左右,也就是说,如果不去刻意选取特别好或者特别差的随机种子的话,不同随机种子带来的准确率差异普遍为0.5%。(结果图中底部的每个破折号对应一次跑动)
因此,回到第一个问题,随机种子的不同导致的模型效果分布是怎样的? 答案显然就是:不同随机种子的运行效果分布是相当集中的——这是一个比较令人满意的结果,除非有人刻意去“调”随机种子,不然最后的结果是能够比较反应模型效果的。
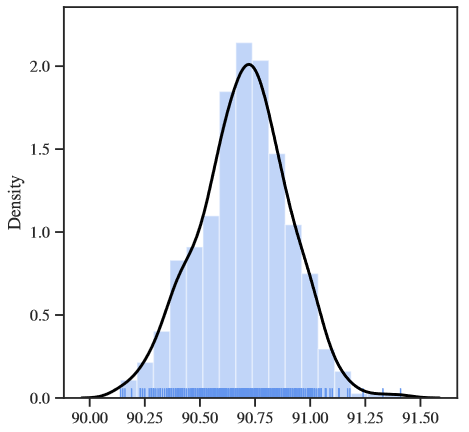
2、是否存在“黑天鹅事件”?

作者发现:
- 模型训练长比训练时间短效果更好。此外,在短训练时间条件下,准确率最小值和最大值相差为1.82%。(可以说在深度学习领域里差距比较大了)
- 10000个随机种子的结果发现,准确率主要位于89.5%至90.5%的区间中。如果不扫描大量的种子,就不可能获得更高或更低的极端值。话虽如此,仅通过扫描前10000个随机种子得到的极值并不能代表该模型正常的结果。
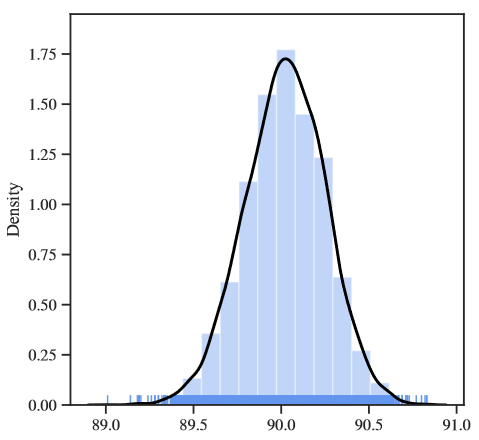
因此,回到问题二:是否存在黑天鹅事件?显然,黑天鹅是存在的。确实有种子表现得比较好或者比较差,这是一个比较令人担忧的结果,因为当前深度学习社区内,大多文章都是追求模型效果的,而这种较好的效果可能仅仅是由于随机种子引起的。
3、在更大的数据集上进行预训练是否可以减少由选择种子引起的差异性?
为了验证大规模数据集对于种子造成模型精度的差异性,作者接着在ImageNet数据集进行实验,得到了如下结果:

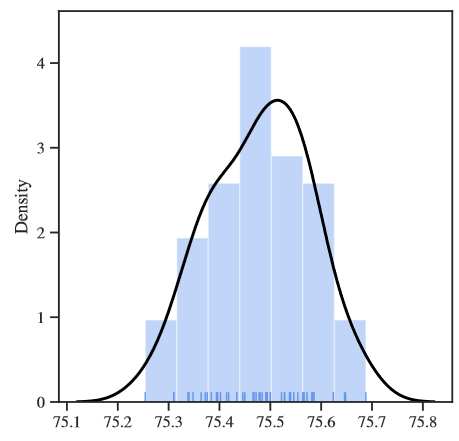
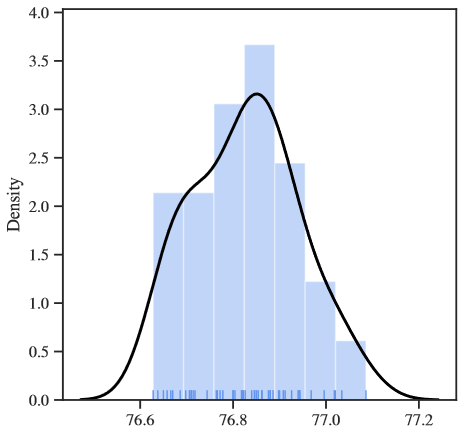
作者发现:
- 大数据集的上的结果标准差是比CIFA 10小得多的,根据上表还是能够观察到大约0.5%的结果提升——这仅仅是由于随机种子引起的。然而,0.5%的准确率提高在CV领域已经可以算是很明显的提升了。
- ImageNet数据集上的结果与CIFAR 10的分布还是有比较大的差异——这是由于随机种子仅仅选了50个的原因。然而,作者认为,哪怕是测试更多的随机种子,准确率分布的差异也不会达到1%以上。
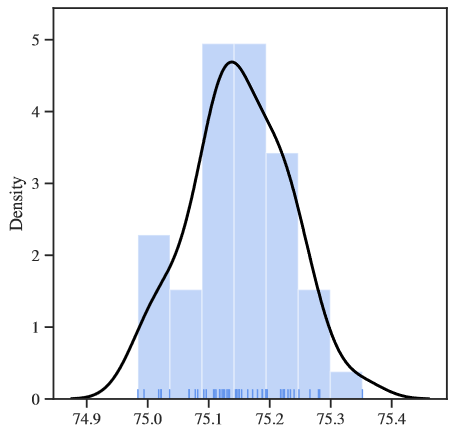
3、在更大的数据集上进行预训练是否能减少由选择种子引起的差异性?
原文作者写到:它确实减少了因使用不同种子而产生的变异,但它并不能减轻这种变异。在Imagenet上,我们发现最大和最小精度之间的差异约为0.5 %,这通常被社区认为是该数据集的显著性。说白了,这个并不是一个符合作者预期的结果,因为目前预训练模型在CV领域里是广泛使用的,哪怕是用的同一个预训练模型,只要你扫描50个随机种子进行测试,你还是能够得到比较好的结果。
思考
下次做实验时设置这个可能会提升代码模型的精确度😎😎😎
1 | torch.manual_seed(3407) |
论文地址:https://arxiv.org/abs/2109.08203
