
I will graduate with a Master’s degree from the School of Electronic Engineering at Xidian University in Xi’an, Shaanxi, under the supervision of Professor Cheng Deng. I completed my undergraduate degree at the School of Electronic Engineering, Xidian University in Xi’an, Shaanxi. Including co-authored works, I have published 6 academic papers Google Scholar Citations: loading….
🎓 Education
- 2024.06 - Present,
 School of Electronic Engineering, Xidian University, Xi’an, Shaanxi, Master’s Degree
School of Electronic Engineering, Xidian University, Xi’an, Shaanxi, Master’s Degree - 2020.09 - 2024.06, School of Electronic Engineering, Xidian University, Xi’an, Shaanxi, Bachelor’s Degree
📝 Publications
arXiv 2026
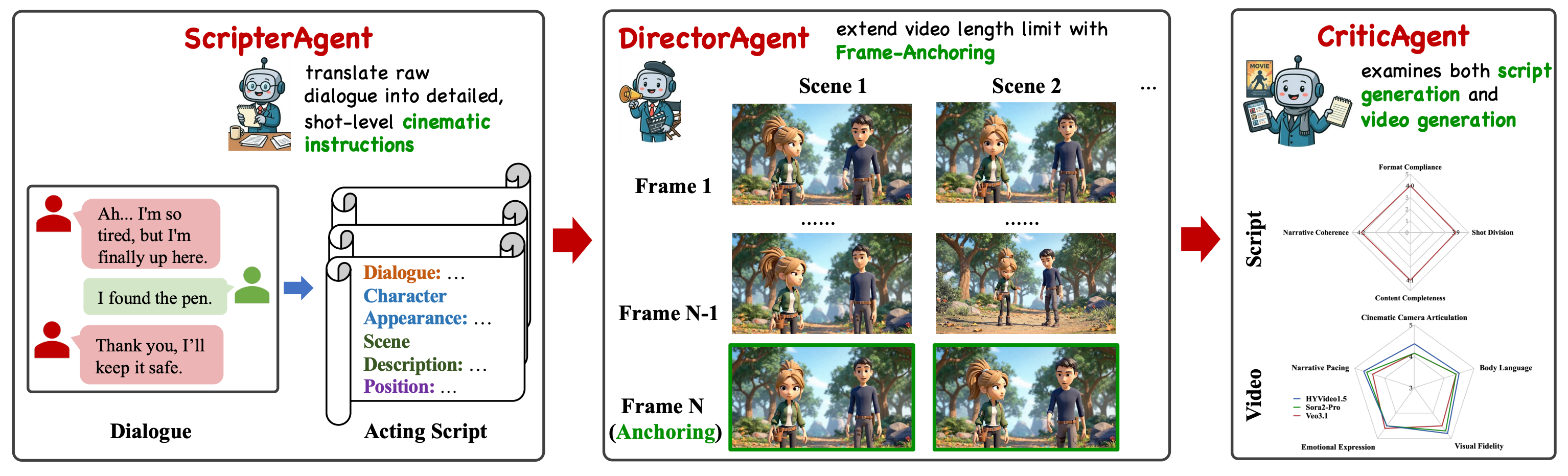
Chenyu Mu*, Xin He*, Qu Yang*, Wanshun Chen, Jiadi Yao, Huang Liu, Zihao Yi, Bo Zhao, Xingyu Chen, Ruotian Ma, Fanghua Ye, Erkun Yang, Cheng Deng, Zhaopeng Tu†, Xiaolong Li, and Linus. The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation. [Paper Link]
arXiv 2025
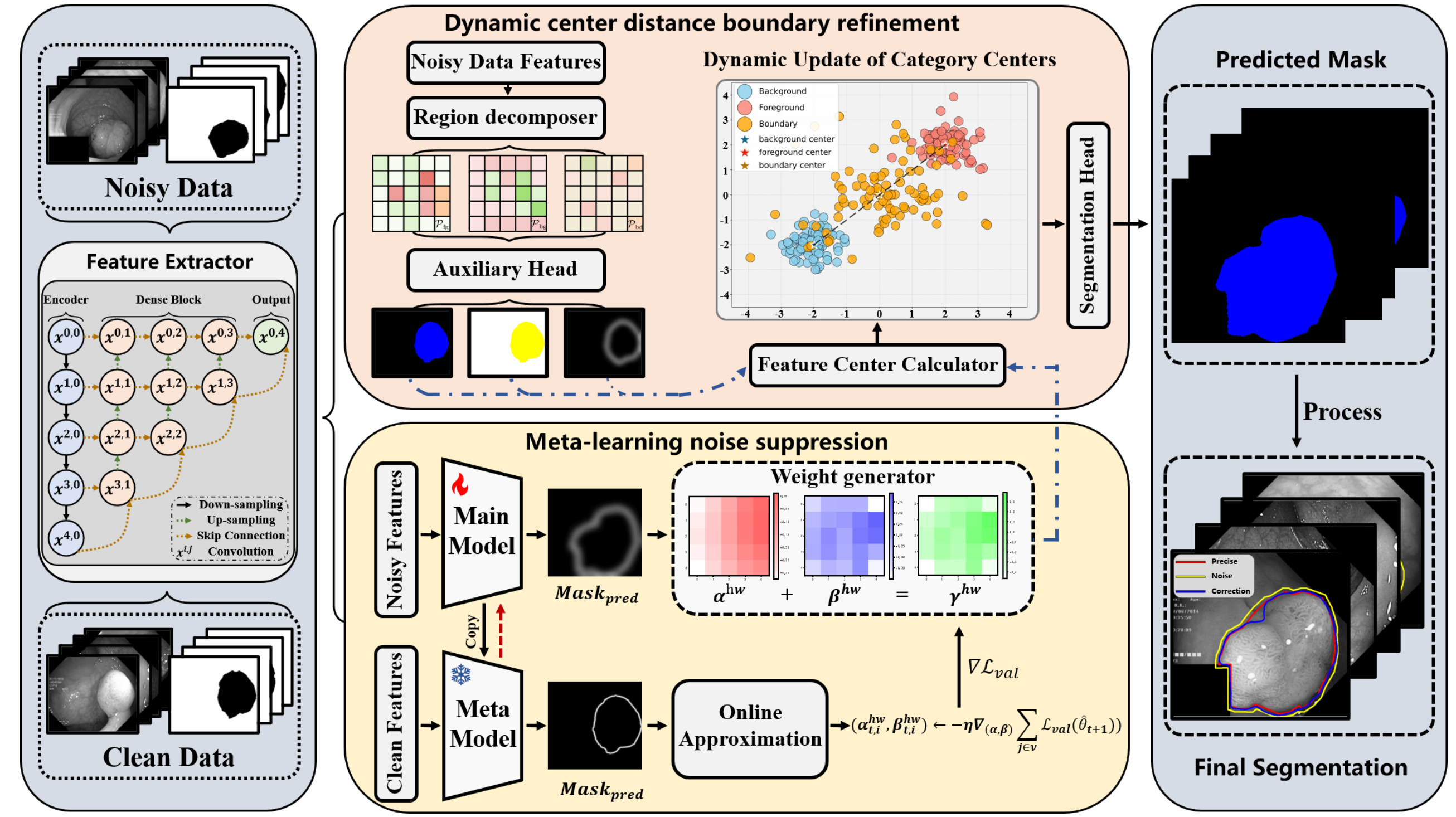
Chenyu Mu, Guihai Chen, Xun Yang, Erkun Yang†, Cheng Deng†. Not All Pixels Are Equal: Pixel-wise Meta-Learning for Medical Segmentation with Noisy Labels. [Paper Link]
ICCV 2025
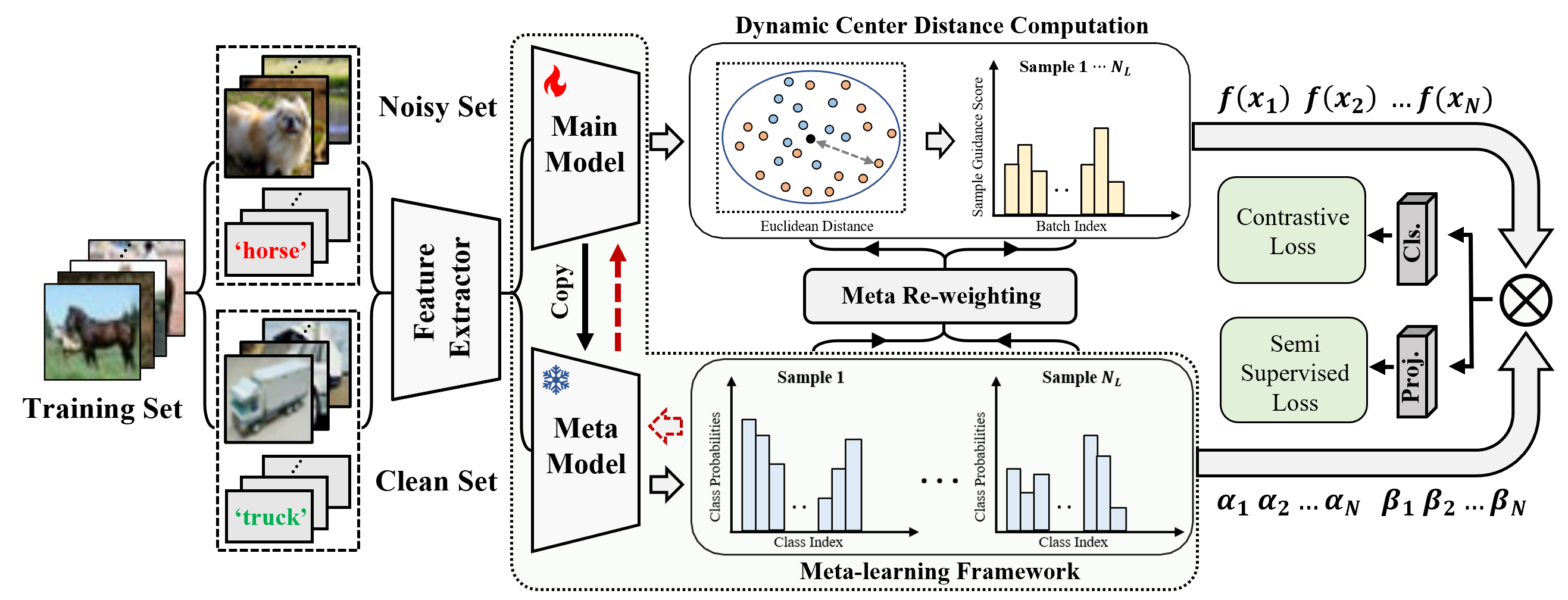
Chenyu Mu, Yijun Qu, Jiexi Yan, Erkun Yang†, Cheng Deng. Meta-Learning Dynamic Center Distance: Hard Sample Mining for Learning with Noisy Labels. [Paper Link][Supplementary Material]
SIGIR 2025
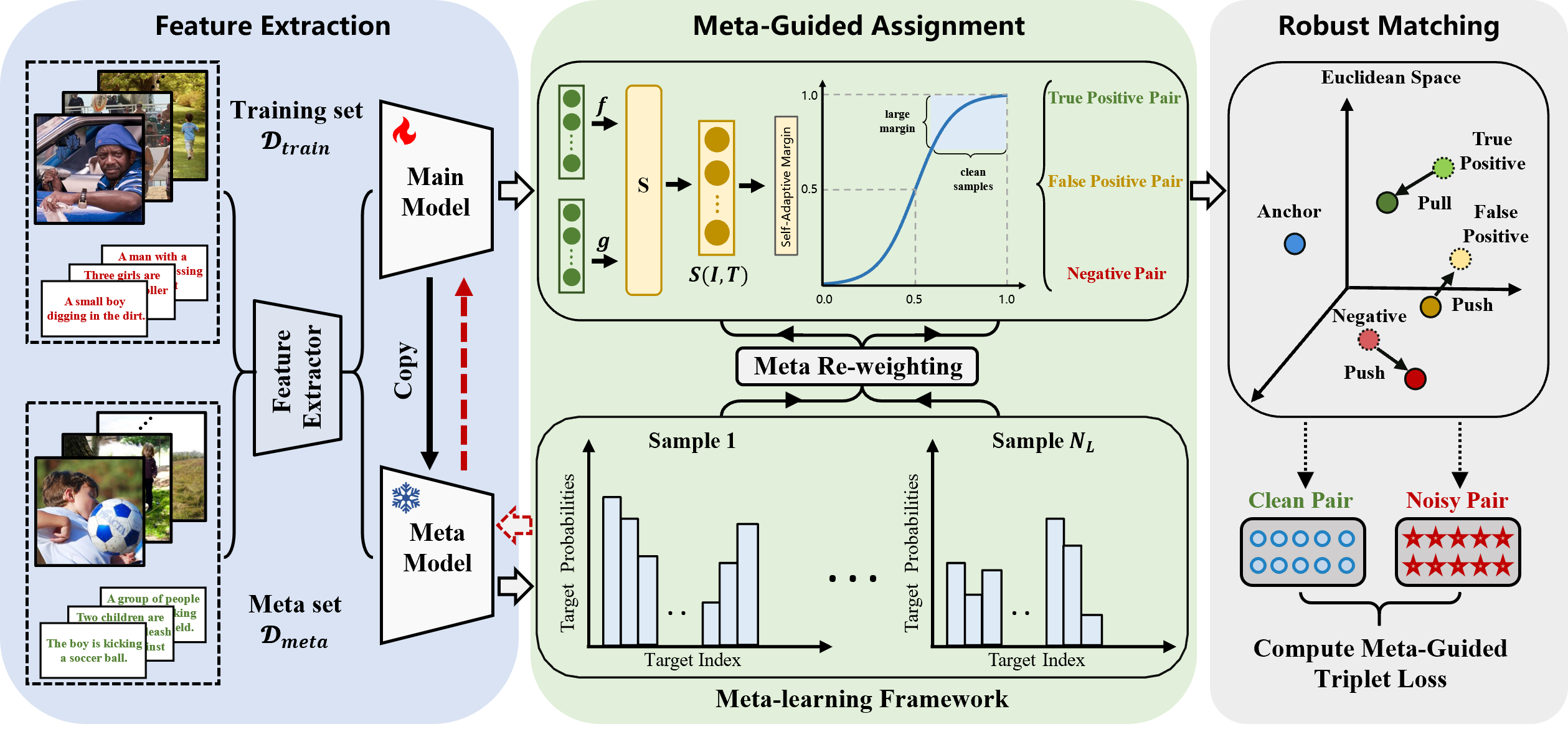
Chenyu Mu, Erkun Yang†, Cheng Deng. Meta-Guided Adaptive Weight Learner for Noisy Correspondence. [Paper Link]
AAAI 2025
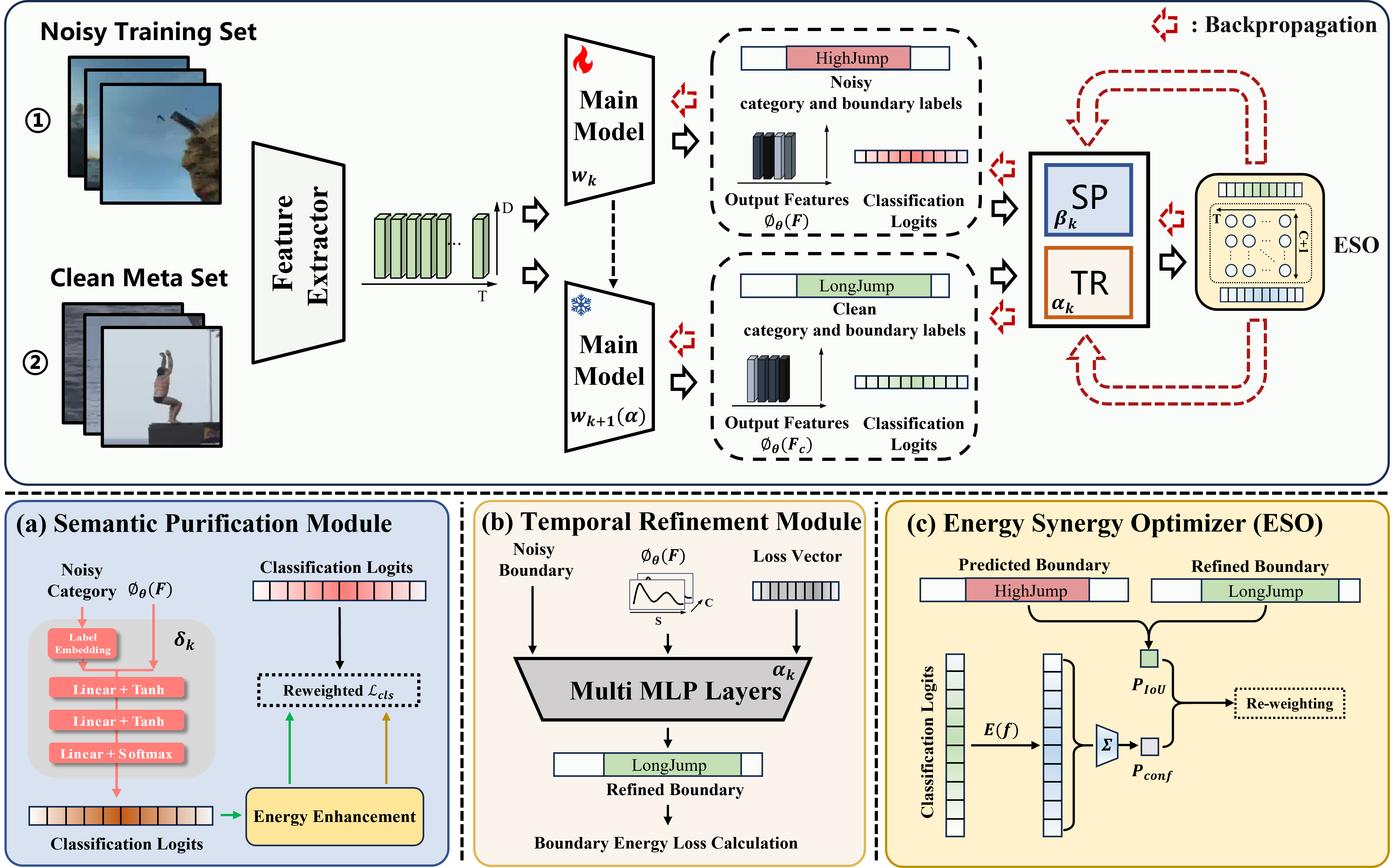
Chenyu Mu*, Jiahua Li*, Kun Wei†, Cheng Deng. Energy vs. Noise: Towards Robust Temporal Action Localization in Open-World. [Paper Link]
Journal of Hazardous Materials 2025
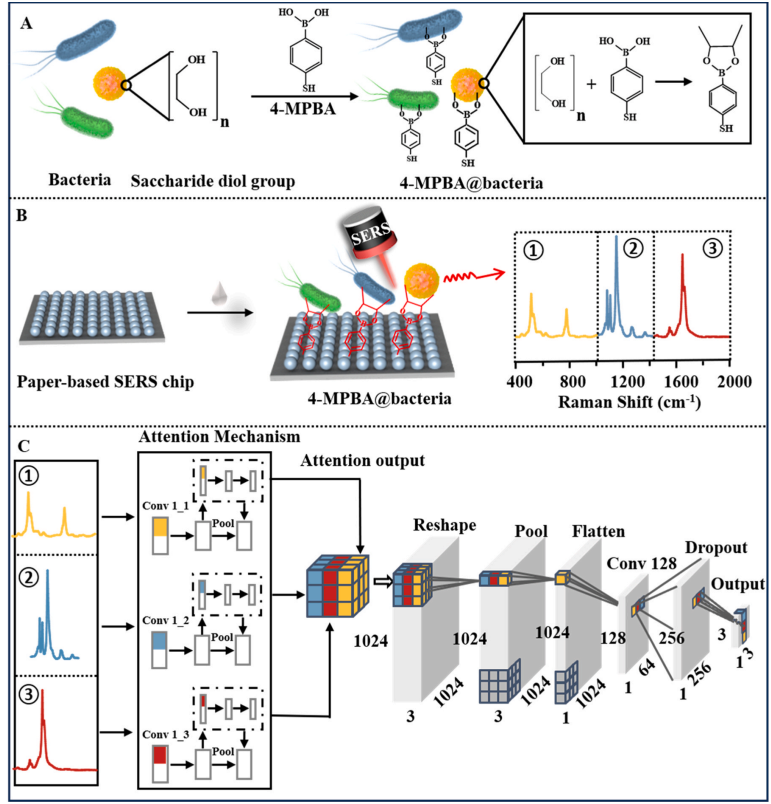
- Liyan Bi*, Huangruici Zhang*,
Chenyu Mu*, Kaidi Sun, Hao Chen, Zhiyang Zhang, Lingxin Chen. Paper-based SERS chip with adaptive attention neural network for pathogen identification. [Paper Link]
🏛️ Academic Conferences
- 2025.07, ACM International Conference on Research and Development in Information Retrieval (SIGIR 2025), Padova, Italy, Invited to give oral presentation
💻 Work Experience
- 2026.04 - Present, Tencent, WXG, Shenzhen
- 2025.12 - 2026.04, JD.com, Explore Academy, Beijing
- 2025.07 - 2025.12, Tencent, TEG Hunyuan, Shenzhen